Ссылка на оригинал: http://myfotomx.com/dalth/linuxbook.odt
Автор: Артем Капитула (no-dashi, dalth & viking).
Скачано с http://myfotomx.com/dalth: 15.07.07
C версии: 1.1
Я много лет работал с Linux, и, общаясь со многими единомышленниками, сделал один странный вывод: нам катастрофически не хватает документации. Причем не инструкций вида «сделайте так и вот так» и не справочных руководств, а некоторого «мостика» между новичком, который видел только графическую оболочку подобную GNOME или KDE, и профессионалом, который может скомпилировать необходимый ему драйвер, даже если этот драйвер упорно сопротивляется.
Соответственно, я попытался сделать попытку написать книжку (хотя на книгу этот материал не тянет, скорей на методичку), которая позволила бы сравнительно просто перейти с пользовательского уровня знакомства с Linux на более высокий уровень, не проходя по типичным ошибкам, и за сравнительно короткое время.
Некоторое время я использовал фрагменты этой книги также как часть учебного курса в Челябинском Государственном университете (ЧелГУ) для того, чтобы мои студенты могли ориентироваться в системе несколько лучше, чем на уровне команд ls/ps/exit. Конечно, если честно – как учебное пособие эта маленькая книга непригодна, но, как мне кажется, она неплохо подходит как дополнительная литература.
Если у вас есть пожелания и дополнения – пишите мне почтой на dalt74@gmail.com, я постараюсь учесть ваши замечания в следующей редакции. Большое спасибо всем тем кто участвовал в рецензировании и помогал советами и замечаниями.
Искренне ваш, Артем Капитула (no-dashi, dalth & viking)
P.S. если вы будете распечатывать или выкладывать это пособие – пожалуйста, указывайте ссылку на автора и оригинальный источник, договорились?
P.P.S. пока что есть следующий to-do list: основы DNS, базовые настройки серверов и рабочих станций под типичные нужды. Ориентировочный срок следующей редакции – через три месяца.
Ядро Linux является единственным процессом, имеющим непосредственный доступ к аппаратуре – все остальные процессы обращаются к устройствам только через ядро. В ядре Linux можно выделить несколько важных подсистем: подсистему управления памятью; планировщик задач; подсистему VFS – виртуальную файловую систему и драйверы.
Подсистема управления памятью управляет распределением оперативной памяти между задачами, а также обслуживает файл подкачки, планировщик задач управляет разделением процессорного времени между задачами (процессами и нитями), подсистема VFS предназначена для обслуживания файловых операций.
Драйверы предназначены для управления устройствами и поддержки различных протоколов. Существует две разновидности драйверов – статически подключенные в ядро драйверы и загружаемые модули; первые всегда загружены, вторые могут быть загружены при необходимости и выгружены, когда необходимость в них отпала. Каждый модуль и само ядро содержат сигнатуру версии – специальную метку, которая описывает версию ядра и некоторые опции, использованные при компиляции ядра. Кроме того, ядра версии 2.6 могут поддерживать цифровую подпись модулей. Это было сделано для повышения надежности системы – по умолчанию ядро не будет загружать и использовать драйверы, предназначенные для другой версии ядра, или собранные с другими опциями, поскольку это может привести к возникновению проблем. Версию ядра можно узнать с помощью команды uname:
|
В принципе, утилиты для работы с модулями поддерживают возможность загрузки модулей, собранных для другого ядра – но пользоваться этой возможностью следует с крайней осторожностью, поскольку это может привести к непредсказуемым последствиями – от ошибок ядра (kernel panic) и вплоть до странных потерь данных и непонятных ошибок, взявшихся на пустом месте.
В большинстве дистрибутивов образ ядра располагается в каталоге /boot, а загружаемые модули ядра располагаются в /lib/modules/<версия_ядра>, там же располагается таблица зависимостей модулей, поскольку некоторые модули могут нуждаться для своей работы в других модулях (например, драйвер поддержки SCSI-дисков нуждается в драйвере поддержки SCSI – как следствие этого, если объекты какого-либо модуля используются другим драйвером, такой модуль невозможно выгрузить). Следующий листинг демонстрирует достаточно типичное содержание каталога модулей для ядер линейки 2.6:
|
Бинарные файлы модулей содержатся в подкаталоге kernel, и имеют расширение “.o” для ядер линейки 2.4 и расширение “.ko” для ядер линейки 2.6. В файлах modules.***map перечисляются символы (функции и переменные), экспортируемые модулями.
Часто в одном каталоге с модулями содержатся ссылки на каталоги, в которых хранились исходные тексты ядра и в котором производилась сборка ядра (это ссылки source и build, соответственно). Эти ссылки, как правило, используются для того, чтобы скомпилировать модули или программы, которые зависят от версии ядра (например, эти ссылки используются при инсталляции модуля поддержки видеокарт nvidia).
Учет взаимосвязей между загруженными модулями производится с помощью счетчика ссылок – модуль увеличивает свой счетчик ссылок как только какой-либо его объект начинает использоваться другими драйверами. Когда объекты модуля освобождаются, счетчик ссылок уменьшается. Модуль может быть выгружен, если число ссылок на него станет равно 0. В ядрах версии 2.6 существует возможность произвести принудительную выгрузку модуля даже если он используется, но этим пользоваться без крайней необходимости не рекомендуется, поскольку очень возможно возникновение ошибок.
Ядро содержит множество переменных и функций, которые используются различными драйверами, и соответственно, если какой-либо драйвер должен обратиться к такому объекту, он должен знать его адрес. Некоторые драйверы также содержат переменные и функции, которые должны быть доступны другим драйверам, и адреса таких объектов тоже размещаются в специальной таблице. При загрузке модуля ядро и программа загрузки модулей устанавливает адреса всех объектов, в которых нуждается загружаемый модуль, и только после этого модуль может начать инициализацию.
Загрузка модулей и их выгрузка осуществляются утилитами modprobe, insmod и rmmod. Программы modinfo и depmod предназначены для получения служебной информации о загружаемых модулях. В процессе своей работы эти утилиты опираются на конфигурационные файлы /etc/modprobe.conf (для ядер 2.6.X) или modules.conf (для ядер 2.4.X).
Для компьютеров архитектуры x86 последовательность загрузки хорошо описана в специализированной литературе, но мы все-таки кратко ее повторим. После включения компьютера первым загружается BIOS. Он тестирует аппаратуру и инициализирует устройства. После этого BIOS прочитывает начальный сектор загрузочного жесткого диска (MBR), убеждается что он содержит код первичного загрузчика, и передает управление прочитанному коду. Кроме кода первичного загрузчика, начальный сектор также может содержать таблицу разделов жесткого диска.
В задачи первичного загрузчика входит чтение основного кода загрузчика операционной системы и передача управления ему, после чего основная часть загрузчика может считать конфигурационный файл, загрузить ядро операционной системы, установить параметры для ядра и передать ядру управление. Ядро инициализирует драйверы, проверяет параметры и, опираясь на параметры, пытается смонтировать корневую файловую систему, после чего (если не было проинструктировано об ином) запускает программу /sbin/init. Дальнейшая работа init подробно описана во множестве книг и статей.
В настоящий момент в мире Linux наиболее распространен загрузчик GRUB. Этот загрузчик состоит из нескольких частей – первичного загрузчика, собственно основного кода который организует интерфейс пользователя, и набора мини-драйверов различных файловых систем, позволяющих прочесть необходимые файлы с файловой системы в момент когда операционная система еще недоступна. Каждая из этих компонент работает на одном из двух этапов загрузки. Рассмотрим эти этапы:
Этап 0 – здесь срабатывает первичный загрузчик GRUB. Он компактен и умещается в один блок жесткого диска, что позволяет при желании разместить его в MBR. В задачи кода stage_0 входит прочтение кода необходимого на следующем этапе (собственно кода загрузчика и мини-драйвера файловой системы где расположены основные файлы загрузчика), и передача управления прочитанному коду.
Этап 1 – это на этом этапе первичным загрузчиком в память уже загружен основной код загрузчика, а также мини-драйвер файловой системы, на которой расположены конфигурационные файлы загрузчика, ядро и необходимые драйверы. Основной код, используя функции мини-драйвера, прочитывает конфигурационный файл и организует диалог с пользователем. В зависимости от выбора пользователя, используя мини-драйвер файловой системы, с диска прочитываются файлы ядра и необходимых драйверов, после чего управление передается ядру. Как вариант, пользователь может отказаться от загрузки Linux и инструктировать GRUB прочесть загрузочный сектор некоторого раздела жесткого диска и передать управление ему.
Первичный загрузчик из состава GRUB может быть расположен как в MBR, так и в загрузочном секторе какого-либо раздела жесткого диска – или даже храниться в файле и быть вызван из другого загрузчика (например NTLOADER).
Нередко случаются ситуации, когда корневая файловая система располагается на устройстве, чей драйвер скомпилирован в виде модуля, или драйвер корневой файловой системы скомпилирован в виде модуля. Получается замкнутый круг – чтобы смонтировать корневую файловую систему систему, необходимо прочесть драйвер, а чтобы прочесть драйвер – нужно смонтировать корневую файловую систему. Чтобы разорвать этот порочный круг, в Linux была введен поддержка initrd – INITial RamDisk.
Initial ramdisk – это файл, который прочитывается загрузчиком ОС и загружается в память вместе с ядром. Ядро интерпретирует фрагмент памяти, куда загружен этот файл, как блочное устройство с помощью специального драйвера, статически вкомпилированного в ядро. После инициализации статически скомпилированных драйверов ядро монтирует файловую систему, хранящуюся в initrd и загружает с нее драйверы и запускает программы, необходимые для монтирования корневой файловой системы.
Обычно файл с образом ядра хранится в каталоге /boot и называется vmlinuz-<версия>, там же располагается файл initrd-<версия>.img, содержащий образ файловой системы initrd. Для каждой версии ядра необходим свой образ initrd, в который включены модули для этой версии ядра. В большинстве случаев образ initrd поставляется в бинарном пакете вместе с ядром, или автоматически создается в процессе построения ядра из исходных текстов в момент выполнения команды make install, если же возникает ситуация, когда необходимо повторно собрать образ initrd (например, в сервере сменили SCSI-контроллер), можно воспользоваться специальной командой mkinitrd, позволяющей произвести повторную генерацию initrd:
|
Для Linux существует два основных загрузчика – LILO и GRUB. Второй является более поздней разработкой и немного удобней в использовании, а LILO используется по историческим или личным причинам (например, он нравится системному администратору), либо в некоторых случаях, когда требуются специфичные для LILO функции. Для более подробной справки лучше обратиться к справочному руководству (man grub, man lilo).
Из интересных особенностей GRUB и LILO следует отметить то, что и оба этих загрузчика, и ядро оперируют термином корневой файловой системы – но если с точки зрения ядра эта та файловая система, которая содержит программу /sbin/init, то с точки зрения обоих загрузчиков корневой файловой системой является та, которая содержит образ ядра и файл initrd.
Подсистема виртуальной памяти управляет распределением оперативной памяти между задачами (процессами). Каждая задача считает, что ей выделен непрерывный участок памяти максимального размера, поддерживаемого на соответствующей архитектуре (для архитектуры x86 это 4GB). Из них последний гигабайт резервируется для себя ядром, часть отдается под код программы и разделяемые библиотеки (оба этих фрагмента ядром защищаются), а оставшееся пространство отдается собственно программе под ее данные – но это только то, как видит это все программа.
На самом же деле программа занимает только тот объем памяти, с которым она реально работает. Большинство памяти существует только “на бумаге”, т.е. будет предоставлена программе в тот момент, когда она обратится в эту область. Ядро распределяет память страницами фиксированного размера. Процедура, когда страница оперативной памяти объявляется частью адресного пространства процесса, называется отображением этой страницы в адресное пространство процесса.
Соответственно, ядро отображает реально используемые страницы в виртуальное адресное пространство процесса. Когда процесс обращается к некоторой странице своего адресного пространства, ядро проверяет, имеет ли он право на доступ к этой странице, и если проверка пройдена и доступ получен, то ядро переадресовывает обращение на реальный адрес этой страницы. Если это первое обращение к странице, ядро попытается найти свободную страницу и в случае успеха отобразит ее в адресное пространство соответствующего процесса. Размер страницы фиксирован архитектурой процессора, и для x86 ее размер составляет 4096 байт.
Если случается ситуация, когда свободных страниц больше нет, но существует файл подкачки, ядро может убрать одну из наиболее долго не использовавшихся страниц в файл подкачки, и освободившуюся физическую страницу отдать запросившему память процессу. Если же нет ни незанятого пространства в файле подкачки, ни свободных страниц RAM, то развитие событий может быть следующим: либо запросивший память процесс прерван и “убит” системой, либо какой-то другой из процессов (это определяется специфическими алгоритмами) будет “убит” ядром, и освободившаяся память будет передана запросившему память процессу.
На самом деле большинством действий занимается одна из подсистем процессора, называемая MMU – Memory Management Unit, и в действительности ядро просто полагается на его работу и вмешивается в нее только для проведения операций пейджинга (подгрузки/выгрузки страниц в SWAP-файл), или когда возникает ошибка доступа к странице.
Ограничение адресного пространства в 4GB не означает, что система не сможет адресовать более этого объема памяти. На платформе x86 ядро Linux может использовать до 64GB, а ограничение в 4GB накладывается лишь на размер адресного пространства процесса.
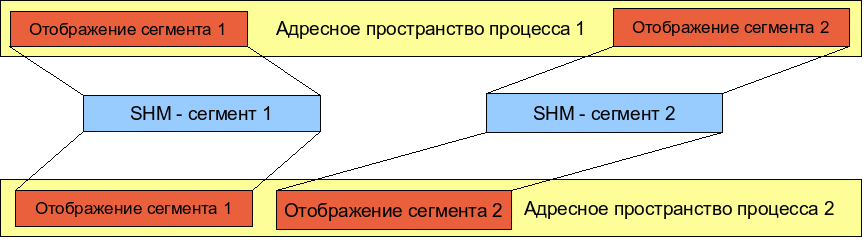
Linux поддерживает стандартную для всех UNIX-подобных операционных систем организацию разделяемой памяти. Пользовательские приложения могут создавать сегменты разделяемой памяти, которые могут быть присоединены к некоторому фрагменту адресного пространства процесса. Любой процесс, имеющий достаточные права доступа, может присоединиться к сегменту разделяемой памяти, и отобразить его в свое адресное пространство, начиная с некоторого адреса.
Если в приведенной схеме любой из процессов изменит содержимое памяти в области, занимаемой отображением одного из сегментов, то же самое изменение произойдет в адресном пространстве другого процесса, поскольку соответствующий сегмент существует в одном экземпляре и отображен в адресное пространство обоих процессов.
Кроме System V IPC ядро Linux также поддерживает другие объекты IPC, в частности семафоры и очереди сообщений. Каждый объект System V IPC идентифицируется уникальным ключом. Просмотреть список всех объектов IPC можно командой ipcs. Команда ipcrm позволяет удалять объекты IPC, которые по каким-либо причинам остались не освобожденными после завершения создавшего их процесса – например, такая ситуация может возникнуть после аварийного завершения работы СУБД Oracle, Informix или DB2.
Соответственно, перед перезапуском процесса системный администратор с помощью команды ipcrm должен освободить неиспользуемые объекты IPC, поскольку стартующее приложение не сможет их повторно создать и не будет корректно работать.
Для каждого объекта IPC система устанавливает права доступа, как если бы это был файл (т.е. для каждого объекта IPC можно устанавливать набор прав ugo/rwx, но в отличие от обычных файлов сменить права доступа для IPC-объектов можно только вызывая специализированные функции, предназначенные для работы с такими объектами.
|
Поддержка System V IPC позволяет сравнительно легко переносить на Linux приложения, написанные для других UNIX-систем.
VFS и драйверы файловых систем являются одной из важнейших составляющих ядра. Для того, чтобы получить доступ к файлам, хранящимся на каком-либо устройстве хранения данных, необходимо, чтобы в ядро был загружен драйвер соответствующей файловой системы, и файловая система была смонтирована. Драйвера всех файловых систем поддерживают набор стандартных функций: открыть файл по имени, записать данные в файл, прочитать данные из файла, закрыть файл, удалить файл и т.д.
Уточним, что драйвера файловых систем не занимаются кэшированием, этим занимается VFS.
При первоначальной загрузке драйвер файловой системы регистрирует в VFS имя файловой системы и те функции, которые предназначены для выполнения стандартных файловых операций. Впоследствии при обращении к файлу на какой-либо файловой системе VFS будет переадресовывать обращение на соответствующую функцию, если таковая была зарегистрирована драйвером. Посмотреть список обслуживаемых ядром файловых систем можно в файле /proc/filesystems:
|
Операция монтирования предназначена для того, чтобы сделать доступной файловую систему, расположенную на каком-либо блочном устройстве. Суть операции монтирования заключается в том, что ядро ассоциирует некоторый каталог (называемый точкой монтирования) с блочным устройством и драйвером файловой системы. Для этого оно передает ссылку на блочное устройство драйверу файловой системы, и в случае, если драйвер успешно проидентифицировал эту файловую систему, ядро заносит в специальную таблицу монтирования информацию о том, что все файлы и каталоги, чей полный путь начинается с указанной точки монтирования, обслуживаются соответствующим драйвером файловой системы и расположены на указанном блочном устройстве.
Некоторые файловые системы не нуждаются в блочном устройстве, поскольку хранят свои данные исключительно в памяти, например файловая система procfs, через файлы которой можно получить доступ к различным системным параметрам и таблицам.
Очень часто при монтировании файловой системы системный администратор имеет возможность задать опции монтирования. Опции монтирования – это специальные параметры, которые влияют на работу драйвера файловой системы, когда он работает с файловой системой на соответствующем блочном устройстве – например, с помощью опций монтирования можно управлять режимом кэширования данных, преобразованиями имен файлов и данных, включать и отключать поддержку ACL и т.д.
Посмотреть таблицу примонтированных файловых систем можно через файл /proc/mounts:
|
Виртуальная файловая система Linux различает несколько типов файлов: каталоги, обычные файлы, именованные каналы, символьные ссылки, сокеты и специальные файлы. Каждая из этих разновидностей обрабатывается своим собственным образом:
Обычные файлы могут быть прочитаны, записаны, удалены или отображены в память.
Каталог можно представить как список имен файлов, и для этого списка определены операции добавления элемента в список, удаление элемента из списка, переименование элемента списка.
Именованные каналы являются просто буферами – в него можно записать некоторый объем данных, и прочесть их в том же порядке, в каком они были записаны.
Сокеты являются вариантом именованных каналов, но если у именованного канала буфер только один, то есть нельзя определить какой процесс записал данные в канал, то у сокетов может быть несколько клиентов, один из которых осуществляет управление сокетом и может обмениваться данными с любым из остальных клиентов, а те в свою очередь могут обмениваться данными с диспетчером канала – то есть сокет поддерживает множество независимых буферов, по одному на каждую пару сервер+клиент
Специальные файлы предназначены для того, чтобы осуществлять прямой доступ к устройствам. Подробнее о специальных файлах будет говориться в главе Секреты /dev
Символьные ссылки являются “ярлыками”, которые могут содержать имя другого файла – и тогда операции чтения, записи и открытия/закрытия файла автоматически переадресовываются к файлу, на который указывает символьная ссылка, но в отличие от “ярлыков” Windows (shortcuts), символьные ссылки (symbolic links) не требуют специальных функций при работе – все программы (кроме тех, которые специально предназначены для работы с ними) видят их как обычные файлы, и также их открывают, читают и записывают данные и т.д.
В некоторых файловых системах, которые изначально проектировались для UNIX-подобных систем, есть возможность создавать кроме символьных ссылок еще и жесткие ссылки. Фактически, жесткая ссылка – это второе имя для файла. Жесткие ссылки возможно создавать только в пределах одной файловой системы.
Из-за того, что в VFS присутствует понятие кэширования, перед отключением системы необходимо делать обязательный сброс изменений на диск. Сброс кэша на диск осуществляется в момент размонтирования файловой системы. Кроме того, с помощью команды sync можно в любой момент принудительно сбросить на диск все закэшированные изменения в файловой системе (например, системные администраторы часто делают sync перед загрузкой нового драйвера). Размонтировать файловую систему можно только тогда, когда ни один процесс не удерживает в открытом состоянии файлов с этой файловой системы, а также не находится ни один процесс не имеет рабочим каталогом каталога с размонтируемой файловой системы. При невыполнении этого условия размонтировать файловую систему не удастся:
|
Некоторые файловые системы поддерживают специальные опции, позволяющие принудительно синхронизировать файловую систему при каждой операции чтения или записи. Обычно опции, влияющие на синхронизацию файловой системы, содержат в своем названии слово sync, например приведенная ниже команда инструктирует операционную систему примонтировать некоторый раздел в режиме принудительной синхронизации:
|
Следует учесть, что принудительная синхронизация – это удар по производительности операций записи для файловой системы, смонтированной в таком режиме, поэтому использовать такой его следует осторожно.
Кроме стандартных наборов прав доступа к файлам некоторые файловые системы Linux поддерживают т.н. POSIX ACL – списки контроля доступа POSIX. Эта возможность позволяет гибко управлять доступом к файлу, не ограничиваясь “классическим” набором ugo/rwx. Для того, чтобы использовать на файловой системе POSIX ACL, необходимо смонтировать файловую систему с опцией acl:
|
Возможно также настроить соответствующий параметр для файловой системы, чтобы она поддерживала POSIX ACL по умолчанию:
|
После установки соответствующей опции можно приступать к работе с POSIX ACL. Для работы с ними существует две базовых утилиты: getfacl для получения списка дополнительных атрибутов доступа, и setfacl для установки расширенных атрибутов контроля доступа. Если в выводе команды ls вы видите символ “+” рядом со списком стандартных прав доступа, это означает, что для файла также установлены расширенные атрибуты контроля доступа:
|
Для просмотра значений расширенных атрибутов можно воспользоваться утилитой getfacl. Жирным шрифтом выделен дополнительный атрибут контроля доступа, позволяющий пользователю kiki получить доступ на чтение к файлу .bash_history:
|
Добавим пользователю oracle права на чтение и запись файла .bash_history с помощью команды setfacl, и затем отберем дополнительные права на доступ к указанному файлу у пользователя kiki:
|
Последним шагом сбросим все расширенные атрибуты с файла с файла .bash_history:
|
Расширенные атрибуты позволяют гибко контролировать доступ к файловых объектам, обходя стратегию ugo/rwx пришедшую из “классического UNIX”. Права доступ на файловые объекты могут быть выданы не только пользователю, но и группе.
К сожалению, далеко не все утилиты и файловые системы поддерживают ACL, поэтому при резервном копировании или восстановлении файлов необходимо проверять корректность установки расширенных атрибутов и правильность их переноса.
Для обеспечения сохранности данных и обеспечения целостности файловых систем при неожиданных сбоях были разработаны журналируемые файловые системы. Как правило, у этих файловых систем существует специальная область данных, называемая журналом. Все изменения, которые необходимо произвести с файловой системой, сначала записываются в журнал, и уже из журнала попадают в основную часть файловой системы.
В большинстве случаев журналируются только метаданные файловых систем (служебная информация, обеспечивающая целостность структуры файловой системы – например, изменения в каталогах или служебных таблицах размещения файлов). Некоторые файловые системы позволяют журналировать не только метаданные, но и данные файлов – такой шаг позволяет повысить надежность, но уменьшает скорость записи данных на файловую систему, поскольку каждый блок данных записывается на диск дважды – сначала в журнал, и затем из журнала в основную область файловой системы..
В большинстве случаев, журналируемые файловые системы способны решить проблемы с надежностью при неожиданных сбоях без тех потерь производительности, к которым может привести использование опции sync при монтировании.
В частности, к журналируемым файловым системам, например, относятся EXT3, ReiserFS, XFS, JFS и некоторые другие.
Объединение кэширования файлов и разделяемой памяти позволяет реализовать такое действие, как отображение файла в память. Для простоты можно представить, что файл загружается в кэш, и страницы кэша отображаются в адресное пространство процесса, и в результате любое изменение в том фрагменте адресного пространства, которое занято отображением файла, автоматически попадает в закэшированные данные файла. Когда файл закрывается, закэшированные изменения сбрасываются на диск, изменяя сам файл. Кроме того, в свободное время ядро также постепенно сбрасывает изменившиеся кэшированные данные на диск.
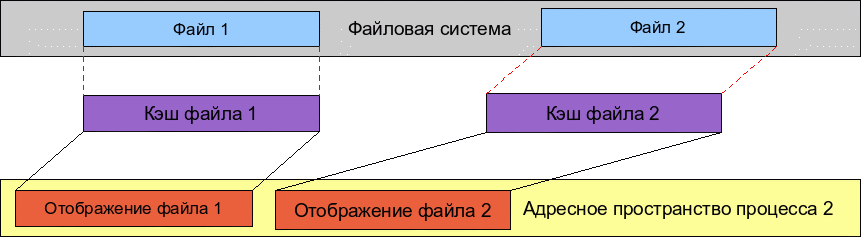
На самом деле, механизм отображения файлов в память куда “хитрее” - при обращении по записи к странице, которая является отображением некоторого файла, ядро перехватывает обращение, производит запись в файл (в подавляющем большинстве случаев эта операция попадает в кэш). При обращении по чтению к такой странице ядро опять же перехватывает обращение и производит чтение из файла – в большинстве случаев это чтение производится из кэша. Для наших же целей проще будет считать, что страницы кэша отображены в память процесса.
Такая методика часто используется для загрузки разделяемых библиотек, когда выполняемый код библиотек и исполняемого кода программы хранится в кэше и через отображение файла в память становится виден в адресном пространстве процесса:
|
На самом деле, драйверы любого устройства и любой файловой системы могут по-своему реализовывать операцию mmap, но большинство драйверов файловых систем полагаются в этом на VFS.
Некоторые типы файловых систем являются специальными и предназначаются для выполнения или реализации специфических задач операционной системы. К таким файловым системам относятся файловые системы procfs и sysfs, предоставляющие доступ к различным параметрам системы и системным объектам, “живущим” в ядре.
Файловая система sysfs в основном предоставляет доступ к объектам ядра и отображает взаимосвязи между ними. Файловая система procfs предоставляет доступ к различным параметрам ядра и драйверов и к пользовательским процессам, позволяя тем самым реализовать такие команды как ps или sysctl. Большинство файлов в sysfs двоичные, в procfs – текстовые.
Драйверы файловых системы ramfs, tmpfs и shmfs очень похожи, и после монтирования файловой системы такого типа на ней можно создавать файлы, хранящиеся в памяти и отличаются в основном небольшими особенностями работы (например, страницы, используемые ramfs под данные файлов, не вытесняются в swap-файл в отличие от shmfs и tmpfs). В ядре 2.6 shmfs была заменена на tmpfs.
Сетевые файловые системы предназначены для получения доступа к файловым системам других компьютеров с использованием сетевых протоколов.
Наиболее часто используются сетевые файловые системы NCPFS (для доступа к серверам Novell NetWare), SMBFS (для доступа к серверам Windows) и NFS (для доступа к файловым системам других UNIX-систем).
Как правило, процедура монтирования сетевых файловых систем схожа с процедурой монтирования обычных файловых систем на блочных устройствах с тем отличием, что вместо блочного устройства указывается адрес сервера, чья файловая система монтируется, и имя монтируемого ресурса. Для примера рассмотрим процедуры монтирования ресурсов, доступных по SMB и по NFS:
|
# mount -t smbfs -o username=usr,workgroup=tst //server/share_name /mnt/smb_target Password: ******** # mount -t nfs -o timeout=4 server:/export/home /mnt/nfs_target |
В данном примере опция -t команды mount указывает тип файловой системы, опция -o позволяет задать дополнительные параметры для монтирования – для SMB мы задаем, например, имя пользователя, с правами которого производится подключение к серверу и имя рабочей группы или домена, для NFS мы указываем таймаут, по истечении которого операция ввода/вывода считается неудавшейся. Вместо блочного устройства мы указываем адрес сервера, ресурс которого хотим использовать, и имя ресурса на сервере. Последним параметром идет точка монтирования.
Для создания файловых систем в Linux используется команда mkfs:
|
На самом деле, mkfs является просто “оберткой” к реальным программам создания файловых систем, которые обычно именуются как mkfs.<имя_ФС>, например mksf.ext2 или mkfs.reiserfs.
В большинстве случаев программы группы mkfs просто инициализируют специальную область раздела, называемую суперблоком файловой системы. Суперблок содержит ссылки на все значимые элементы файловой системы (например, ссылку на оглавление корневого каталога, ссылку список свободных блоков, ссылку на список файлов и т.д.)
Наличие суперблока (который практически всегда содержит в своем теле некоторое характерное значение) позволяет производить монтирование файловых систем без указания их типа. К сожалению, некоторые файловые системы вследствие своей архитектуры не содержат суперблока (в частности, FAT и большинство ее разновидностей) и для блочных устройств, содержащих такие файловые системы, автоматическое определение типа файловой системы затруднено.
Ядро содержит очень много параметров, от которых зависит его производительность и которые могут изменять алгоритмы его работы. Для того, чтобы иметь возможность узнавать и изменять эти параметры, в UNIX был разработан интерфейс sysctl.
Виртуальная файловая система procfs содержит каталог sys с деревом подкаталогов и файлов. Содержимое каждого из этих файлов можно прочесть, например, командой cat, или записать в такой файл новое значение командой echo:
|
Команда sysctl предназначена для того, чтобы избежать необходимости использовать прямой доступ к этим файлам, и предоставить возможность автоматизации установки таких параметров при загрузке системы. На самом же деле, команда sysctl просто читает или записывает значения в файлы из каталога /proc/sys, т.е. если системный администратор устанавливает с помощью команды sysctl значение некоторого параметра, фактически он просто записывает это значение в соответствующий файл. Существует однозначное соответствие между именем параметра и именем файла, через который его можно изменить: если посмотреть вывод sysctl -a, можно увидеть, что параметры в большинстве своем именуются несколькими мнемоническими аббревиатурами, разделенными точками:
|
Если в имени параметра заменить точки на символ разделителя пути (символ “/”), и к началу получившейся строки добавить /proc/sys/ - то мы получим имя файла, через который можно изменить или прочесть значение соответствующего параметра.
Если системному администратору необходимо при каждой загрузке изменять некоторые параметры через интерфейс sysctl, то список параметров и их значений можно записать в конфигурационный файл /etc/sysctl.conf, который прочитывается при каждой загрузке системы.
В Linux исполняемые файлы можно условно поделить на две группы – те, которые содержат в себе весь код, необходимые для работы, и те, которым необходимы разделяемые библиотеки. Первые называют статически собранными бинарными файлами, вторые называют динамически собранными исполняемыми файлами.
Статически собранные программы характеризуются тем, что могут корректно функционировать в любых условиях, и не зависят от наличия или отсутствия разделяемых библиотек, что может оказаться полезным в ситуациях, когда возникают конфликты версий разделяемых библиотек, или когда системные библиотеки повреждены или недоступны (например во время восстановления операционной системы после серьезного сбоя). К недостаткам таких исполняемых файлов следует отнести то, что они имеют значительный размер и для обновления программы необходимо полностью заменить ее исполняемый файл – например, если несколько статически собранных программ, которые работают с архивами ZIP, содержат ошибку, то для исправления ошибки необходимо заменить все эти программы, что может быть затруднено (например, будет трудно точно установить, какие именно программы содержат ошибочный код и нуждаются в обновлении). Кроме того, статически собранные программы не умеют совместно использовать совпадающие участки кода, что ведет к излишнему расходу системных ресурсов.
Динамически собранные исполняемые файлы для корректной работы требуют наличия файлов разделяемых библиотек, и соответственно при их отсутствии/повреждении не могут корректно функционировать, но зато для обновления программы и исправления ошибки часто оказывается достаточным просто заменить соответствующую разделяемую библиотеку, после чего ошибка исчезает во всех программах, которые эту библиотеку используют динамически. Динамически связанные программы также значительно меньше по объему, чем статически связанные, и код разделяемых библиотек может использоваться одновременно многими программами – что позволяет экономить системные ресурсы.
Подавляющее большинство программ в современных дистрибутивах Linux являются динамически собранными. Определить тип исполняемого фала (статический ли он либо с динамическим связыванием) можно, например, с помощью команды ldd:
|
В данном случае мы видим, что исполняемый файл /bin/su использует динамическое связывание, а исполняемый файл /sbin/devlabel собран статическим образом.
Основная системная библиотека, которая так или иначе используется практически всеми программами, называется glibc (GNU libc). Основными задачами glibc являются обеспечение взаимодействия между ядром и пользовательскими процессами, поддержка локализации и многие другие распространенные действия.
На нижнем уровне прикладные процессы могут обратиться к функциям ядра посредством системных вызовов (syscall). Фактически syscall – это вызов прерывания 80h с установленными параметрами, описывающими параметры для этого системного вызова. Те функции glibc, которые должны обратиться к ядру, в большинстве случаев просто устанавливают параметры для соответствующего системного вызова и вызывают int80h.
Большинство программ используют динамически загружаемую библиотеку glibc, но некоторые приложения, которые должны работать вне зависимости от наличия файловой системы, где расположена динамически загружаемая реализация libc, используют статическое связывание, когда весь программный код, необходимый для их работы, содержится в исполняемом файле программы. В основном к таким программам относятся утилиты, используемые при загрузке системы совместно с initrd – например, статические варианты утилит insmod, lvm или devlabel, а также командные оболочки для первичной зарузки или восстановления системы – например sash – standalone shell, часто используемый при восстановлении системы после серьезного сбоя или nash, используемый при выполнении сценариев загрузки после монтирования initrd, но до монтирования корневой файловой системы, когда разделяемая версия glibc еще недоступна.
Существует набор базовых действий, которые практически любая программа выполняет одинаково – открытие файла, чтение и запись данных и тому подобное. Разделяемые библиотеки предназначены для того, чтобы предоставить прикладным программам готовые интерфейсы функций для выполнения каких-либо более-менее стандартных действий. Разделяемая библиотека, как понятно из названия, может использоваться множеством программ. В настоящий момент стандартным форматом для разделяемых библиотек в Linux является ELF (Executable Linked Format).
Каждый файл ELF имеет заголовок, в котором описывается, какие секции содержит этот файл. Секции объединяют однотипные данные, и их детальное описание можно прочитать в справочном руководстве [man elf]. Мы же выделим следующую информацию: каждая библиотека содержит список имен переменных и функций, которые она содержит и предоставляет другим (экспортирует) и список переменных и функций, которые необходимо взять в других библиотеках, а также секции инициализации и деинициализации. Экспортируемые и импортируемые объекты (переменные и функции) называют символами библиотеки.
Большинство исполняемых файлов программ также имеют формат ELF, и на самом деле отличаются от библиотек в основном тем, что не имеют экспортируемых функций. Загрузчик ELF (он же dl, dynamic linker и dynamic loader) умеет загружать в память код ELF-файла, анализировать его структуру для определения списков экспортируемых и импортируемых символов и загружать необходимые для работы программы библиотеки.
Когда пользователь пытается запустить какую–либо программу, первым начинает работу загрузчик ELF. Он загружает в память процесса бинарный файл и выделяет, какие символы и из каких библиотек необходимо догрузить в память. После дозагрузки каждой библиотеки загрузчик связывает символы (проставляет реальные адреса) из загруженной библиотеки и повторяет цикл анализа на предмет того, какую библиотеку нужно загрузить. Когда все нужные библиотеки загружены, загрузчик передает управление коду инициализации каждой из загруженных библиотек в порядке, обратном загрузке, после чего передает управление коду программы. По завершении программы загрузчик снова “проходится” по всем библиотекам и вызывает их функции деинициализации. Если на этапе загрузки какой – либо библиотеке возникает ошибка, загрузчик сообщит об этом пользователю. Наиболее типичные ошибки dl – это не найденный файл библиотеки или неразрешимый символ (символ не был найден в библиотеке, в которой ожидался).
Вполне естественно, что загрузчик ищет библиотеки не по всей файловой системе, а только в определенных каталогах. Это каталоги /lib, /usr/lib и те, которые были перечислены системным администратором в файле /etc/ld.so.conf. Уточним, что этот файл на самом деле используется только системной утилитой ldconfig, сам же загрузчик использует кэш-файл /etc/ld.so.cache. Обновить этот кэш-файл можно путем простого запуска ldconfig без параметров. Следствием этого является то, что если вы установили в систему новые библиотеки, не мешает вызвать ldconfig.
В некоторых дистрибутивах есть возможность включать в ld.so.conf дополнительные файлы без его изменения. Для этого в ld.so.conf включается специальная строка вида:
|
Это приводит к тому, что каталоги, перечисленные в файлах с расширением conf, расположенных в каталоге /etc/ld.so.conf.d будут использованы для поиска разделяемых библиотек:
|
Нередко возникает ситуация, когда пользователю необходимо запустить какую-либо программу, которая не находится в каталогах, описанных в /etc/ld.so.conf. В таких ситуациях можно воспользоваться специальным “люком”, оставленным разработчиками dl специально для таких случаев: дело в том, что кроме загрузки библиотек с использованием данных из ld.so.cache загрузчик проверяет факт наличия библиотеки с указанным именем в каталогах, перечисленных в переменной среды LD_LIBRARY_PATH.
Разработчики часто используют еще одну возможность ld: если файл некоторой разделяемой библиотеки указан в переменной LD_PRELOAD, эта библиотека принудительно загружается и ее символы считаются более “приоритетными” и перекрывают одноименные символы, если таковые существуют в других библиотеках, загружаемых ld при запуске на выполнение бинарного файла ELF.
Попробуем рассмотреть примеры использования указанных возможностей dl: пусть есть некоторый программный продукт, в состав которого кроме собственно исполняемых программ входят разделяемые библиотеки (например, таковы практически все продукты, разработанные с помощью Borland Kylix). Если мы установим такой пакет, например, в /opt/program, его исполняемые файлы в /opt/program/bin а разделяемые библиотеки в /opt/program/lib, то программа, скорее всего, не будет запускаться, поскольку не сможет загрузить необходимых библиотек. Для того, чтобы программы пакета начали запускаться, мы должны “объяснить” ld где именно искать библиотеки. Рассмотрим возможные способы, которыми мы можем воздействовать на ld чтобы добиться нужного нам результата.
Первый способ – указать каталог с библиотеками перед запуском программы и уже затем запустить программу (ld воспользуется значением переменной для того, чтобы попытаться найти библиотеки по указанному пути):
|
Второй способ – добавить каталог /opt/program/lib в файл /etc/ld.so.conf и запустить ldconfig, решив проблему с невозможностью нахождения этих библиотек для всех программ сразу:
|
Можно также воспользоваться возможностью принудительной загрузки тех библиотек, которые необходимы программе для запуска:
|
Большая часть кода разделяемых библиотек находится в кэше и становится доступна процессам через отображение файла в память. Это отображение делается с правами доступа “только чтение”, что защищает код библиотек от переписывания его неправильно работающими или просто злонамеренными программами.
Ядро и его подсистемы очень важны, но большинство пользы приносят прикладные задачи, поэтому мониторинг состояния задач (процессов) – очень важная часть работы системного администратора. В Linux получить информацию о процессах можно через файлы и каталоги файловой системы procfs, как правило монтируемой к каталогу /proc.
Каждому процессу сопоставляется в /proc отдельный каталог, имя которого совпадает со значением PID процесса. Файлы в этом каталоге предоставляют информацию о соответствующем процессе. Таблица приводит список файлов и их назначение:
|
Имя файла |
Формат |
Назначение |
|---|---|---|
|
cmdline |
строка, разделенная символами \0 |
Представляет командную строку, которой был запущен процесс. параметры командной строки отделяются друг от друга символами \0 |
|
environ |
строка, разделенная символами \0 |
Представляет список переменных окружения для указанного процесса |
|
exe |
символьная ссылка |
Ссылается на исполняемый файл процесса |
|
maps |
несколько строк |
Список отображенных в память процесса файлов |
|
mem |
бинарный |
Прямой доступ к адресному пространству процесса |
|
mounts |
несколько строк |
Список примонтированных файловых систем, доступных процессу |
|
stat |
строка числовых значений |
Статистика активности процесса |
|
statm |
строка числовых значений |
Статистика по использованию памяти процессом |
|
cwd |
символьная ссылка |
Ссылается на каталог, который является текущим для процесса |
|
fd/* |
символьные ссылки |
Имена файлов подкаталога fd соответсвуют открытым процессом дескрипторам файлов. Символьные ссылки указывают на соответствующие файлы |
|
root |
символьная ссылка |
Ссылается на каталог, который процесс считает корневым |
|
status |
несколько строк |
Описание состояния процесса |
Все указанные данные полностью соответствуют тому, что показала бы программа ps, будучи запущенной в тот момент, когда просматривается соответствующий файл, поскольку утилита ps на самом деле просто читает данные из соответствующих файлов в /proc.
Linux на самом деле поддерживает только один внутренний механизм создания процессов – механизм fork+exec. Любой процесс, который хочет создать еще один процесс, должен сначала создать свою копию с помощью системного вызова fork, после чего порожденный процесс, который является полной копией предыдущего за исключением нескольких параметров, таких как PID (Process ID) и PPID (Parent Process ID) использует системный вызов exec для того, чтобы загрузить в свое адресное пространство код новой программы и начать его выполнение. Соответственно, все процессы организуют дерево, когда у каждого процесса есть родительский процесс (исключение составляет процесс init, запущеный ядром на этапе загрузки).
Когда процесс завершается, код его завершения возвращается родительскому процессу. До тех пор, пока код завершения процесса не будет прочитан родительским процессом, запись об этом процессе продолжает существовать в таблице процессов в ядре. Такой процесс (уже завершившийся, но еще числящийся в таблице процессов) называют процессом – зомби (zombie process). Завершить zombie process может родительский процесс, прочтя код его завершения. Если у вас в системе появилось множество зомби – процессов, это скорее всего означает ошибку в программе, породившей этот процесс. Удалить процесс – зомби можно только удалив его родительский процесс.
Нередко бывает, что родительский процесс завершается раньше, чем дочерний, и тогда для дочернего процесса объявляется родительским процесс init, и поэтому в системе никогда не бывает процессов-”сирот”, т.е. тех, кто не имеет родителя и чей код завершения некому прочесть.
Ядро Linux реализует поддержку двух типов устройств – символьных и блочных. Основное их отличие в том, что для блочных устройств операции ввода вывода осуществляются не отдельными байтами (символами), а блоками фиксированного размера.
В Linux вся работа с устройствами ведется через специальные файлы, которые обычно расположены в каталоге /dev. Специальные файлы не содержат данных, а просто служат точками, через которые можно обратиться к драйверу соответствующего устройства. У каждого специального файла есть три характеристики – тип устройства (character или block), старший номер устройства (major number) и младший номер (minor number). Для примера, посмотрим на содержимое каталога /dev:
|
Как видно, в листинге присутствует описание семи устройств, четырех блочных и трех символьных. Для каждого файла можно увидеть его тип (первая буква в списке прав доступа), пользователя-владельца, группу-владельца, major number, minor number, дату модификации и имя файла.
Для поддержки работы с устройствами в ядре хранятся две таблицы, одна для списка символьных устройств, другая для списка блочных устройств. Каждая строка таблицы сопоставлена какой-то разновидности устройств соответствующего типа – например, для типа “символьные устройства” можно выделить следующие разновидности: COM-порты, LPT-порты, PS/2-мыши, USB-мыши и т.д., для типа “блочные устройства” можно выделить SCSI-диски, IDE-диски, SCSI-CD-приводы, виртуальные диски которыми представляются RAID-контролеры и т.п.
Каждая ячейка в этих системных таблицах сопоставляется конкретному экземпляру устройства. Таким образом, с точки зрения ядра каждое устройство оказывается однозначно проидентифицировано тремя параметрами – типом устройства (блочное или символьное) и двумя числами – номерами строки и номером столбца таблицы, в которой хранится ссылка на драйвер этого устройства.
Пример таблицы символьных и устройств
|
|
0 |
1 |
... |
63 |
64 |
65 |
66 |
... |
175 |
... |
|---|---|---|---|---|---|---|---|---|---|---|
|
4 |
|
|
|
|
COM1 |
COM2 |
COM3 |
|
|
|
|
6 |
LPT1 |
LPT2 |
|
|
|
|
|
|
|
|
|
10 |
|
Мышь PS/2 |
|
Диспетчер томов LVM |
|
|
|
|
Слот AGP |
|
|
14 |
Микшер первой зв. карты |
|
|
|
|
|
|
|
|
|
|
195 |
Первая видеокарта NVidia |
|
|
|
|
|
|
|
|
|
Пример таблицы блочных устройств
|
|
0 |
1 |
2 |
... |
16 |
... |
64 |
65 |
... |
|---|---|---|---|---|---|---|---|---|---|
|
3 |
IDE Primary Master |
Раздел 1 на IDE Primary Master |
Раздел 2 на IDE Primary Master |
|
Раздел 16 на IDE Primary Master |
|
IDE Primary Slave |
Раздел 1 на IDE Primary Slave |
|
|
13 |
SCSI диск 1 |
Раздел 1 на SCSI-диске 1 |
Раздел 2 на SCSI-диске 1 |
|
SCSI диск 2 |
|
SCSI диск 4 |
Раздел 1 на SCSI-диске 4 |
|
При попытке обращения к такому специальному файлу ядро переадресует обращение через нужный драйвер на устройство в соответствии с теми данными, которые указаны в таблице устройств, причем конкретная таблица устройств будет выбрана в зависимости от типа устройства, строка из таблицы будет выбрана по major number, и столбец будет выбран по minor number. Если мы посмотрим на примеры наших таблиц, то увидим, что обращение на специальный файл /dev/ttyS1, который представляет символьное устройство со старшим номером 4 и младшим номером 65 будет адресовано на последовательный порт COM2, а обращение к файлу /dev/hda2 (блочное устройство со старшим номером 3 и младшим номером 2) будет адресовано на 2-й раздел жесткого диска IDE, работающего в режиме primary master.
В настоящее время существует два подхода к организации /dev – статическая организация и динамическая организация. В первом случае в каталоге /dev заранее создаются специальные файлы для всех возможных устройств вне зависимости от того, загружен драйвер соответствующего устройства или нет. Во втором случае специальные файлы в /dev создаются по мере инициализации устройств и загрузки драйверов, и удаляются при выгрузке соответствующего драйвера или удалении устройства.
Процесс работы со статическим /dev особых проблем не вызывает – системный администратор при необходимости просто создает отсутствующие файлы командой mknod или MAKEDEV. В том случае, когда какая-либо программа обращается к устройству, чей драйвер не загружен (или загружен, но ни одного соответствующего устройства не было обнаружено), операционная система возвращает ошибку при попытке открытия файла такого “неверного” устройства. Ниже приведен пример создания специального файла, соответствующего блочному устройству с мажором 8 и минором 33 и попытка его использования (отметим, что этот специальный файл соответствует разделу на жестком диске, который не существует на тестовой машине, где выполнялись эти команды):
|
Сообщение No such device or address как раз и означает, что записи для данного устройства в таблице блочных устройств не существует.
Ядро Linux совместно с некоторыми системными утилитами поддерживает такую интересную возможность, как загрузка драйверов “по требованию”. Реализуется это следующим образом – в момент, когда какая-либо программа пытается открыть специальный файл, не связанный ни с каким драйвером, ядро делает попытку подобрать соответствующий драйвер самостоятельно. Необходимый драйвер для каждого специального файла определяется в файле /etc/modules.conf путем задания специального алиаса (alias) для модуля. Для активизации автоматической загрузки драйвера какого-либо символьного устройства в большинстве случаев достаточно просто записать в /etc/modules.conf строку следующего вида:
|
Для блочных устройств соответствующая запись слегка меняет свою форму:
|
X и Y – это major и minor специального файла, попытка открыть который должна активизировать автоматическую загрузку драйвера. Владельцы видеокарт на чипе nVidia могут увидеть этот подход в действии – программа инсталляции драйвера nVidia автоматически прописывает в modules.conf запись для загрузки «по требованию» той части драйвера, которая работает в режиме ядра.
Вместо X или Y может также быть подставлен символ “*” , означающий “любое число”. Например, пусть в modules.conf будет написан следующий текст:
|
Тогда при обращении к любому символьному устройству с major number равным 81 и которое не ассоциировано ни с каким драйвером, система попытается загрузить драйвер bttv (драйвер TV-тюнера на основе чипа bt848).
Эта возможность обеспечивает Linux возможность плавной загрузки и эффективного использования ресурсов – драйвер не загружается, пока в нем не возникнет необходимости. К сожалению, за простоту этой схемы приходится платить большим количеством специальных файлов в /dev.
Для того, чтобы избавить администратора от ручного создания специальных файлов и для уменьшения количества файлов в /dev был реализован второй способ организации /dev – динамическое создание специальных файлов процессе загрузки драйверов. Реализовано это было следующим образом:
Ядро монтирует к каталогу /dev специальную файловую систему, называемую devfs – эта файловая система хранится целиком в оперативной памяти и не занимает никакого места на диске. Когда какой-либо драйвер в процессе загрузки или работы обнаруживает обслуживаемое им устройство, он регистрирует это устройство и сообщает о нем драйверу devfs. Драйвер devfs создает специальный файл, который виден прикладным программам и может быть корректно открыт. При выгрузке же драйвер устройства сообщает devfs о том, что соответствующее устройство уже не активно, и драйвер devfs удаляет запись о соответствующем специальном файле из файловой системы devfs.
Файловая система devfs отличается тем, что как правило специальный файл для устройства создается с длинным путем – например, для раздела на scsi-диске путь может выглядеть примерно так: /dev/scsi/host1/bus1/target3/lun4/partition2
Эта особенность является весьма важным плюсом devfs, поскольку она позволяет адресовать дисковые устройства путем указания логического пути их подключения и избежать смены имен SCSI-дисков в некоторых случаях (об этих случаях будет рассказано позднее).
Для того, чтобы организовать более прозрачную структуру каталогов и файлов устройств, используется специальный демон devfsd. Он взаимодействует с драйвером devfs и ядром и в процессе активизации и деактивизации устройств он создает и удаляет символьные ссылки вида /dev/disks/disc0 или /dev/hda1.
Надо отметить, что схема динамического /dev в некотором смысле близка к той организации каталога /dev, которая используется некоторыми коммерческими UNIX-системами (например, в Solaris), когда есть виртуальная файловая система /devices, и на ее файлы создаются ссылки из /dev, только в Linux роль программы cfgadm играет демон devfsd, и все изменения в состав /dev вносятся автоматически.
С помощью devfsd файловая система devfs также реализует автоматическую загрузку модулей, но в этом случае выбор модуля идет не через комбинацию type/major/minor, а путем указания имени запрошенного файла – когда приложение пытается открыть несуществующий файл устройства, devfs передает имя запрошенного файла демону devfsd, и последний загружает необходимые модули, например такой код в файле modules.devfs:
|
Приведет к тому, что при попытке обращения к любому файлу, чей полный путь начинается строкой /dev/nvidia, будет произведена попытка загрузить драйвер nvidia.o (для ядра 2.6 nvidia.ko)
В принципе, на сегодняшний день выбор того, каким именно образом необходимо организовывать /dev, остается за пользователем и создателем дистрибутива. Например, в Mandrake Linux используется devfs, а в RedHat, Fedora и SUSE каталог /dev организован статическим образом, а опытные пользователи часто меняют способ организации /dev в зависимости от своих предпочтений.
В современных дистрибутивах и ядрах поддержка devfs/devfsd отключена, и на смену этой паре пришел специальный демон, называемый udev. В отличие от devsfd, который требовал поддержки со стороны ядра, udev такой поддержки не требует. При инициализации устройства ядро подает сигнал через файловую систему sysfs, и демон udevd, получив сигнал об этом событии, самостоятельно создает соответствующий специальный файл устройства в каталоге /dev в соответствии с правилами, описанными в его конфигурационных файлах. При необходимости в этих файлах можно указать например вызов некоторой внешней программы, создание символьной ссылки и так далее.
Например, если некоторое устройство после подключения перед началом работы требует дополнительной настройки с использованием внешних программ, можно создать соответствующее правило для udev, в котором будет указано какую программу вызвать и какие параметры ей необходимо передать – в частности, это может потребоваться для data-кабелей к некоторым мобильным телефонам Nokia, для устройств которым для корректной работы требуется firmware, или для сохранения или восстановления текущих настроек устройства.
Тем не менее, несмотря на внешние отличия между статической организацией /dev, devfs и udev, следует помнить что это всего лишь способ заполнения каталога /dev, и во всех случаях в конечном итоге на файловой системе создаются те же самые файлы символьных и блочных устройств.
Любое устройство, подключенное к компьютеру, имеет свое назначение, и блочные устройства в большинстве своем предназначаются для хранения информации. Как организована работа с блочными устройствами в Linux?
Во-первых, следует определиться с типами блочных устройств. Их следует поделить на две категории: к первой отнесем логические (виртуальные) устройства (loop-устройства, software RAID-устройства, устройства Volume Management, поддержка различных таблиц разделов), ко второй категории - физические устройства (SCSI диски и CD-ROM'ы, IDE-диски, USB-storage, RAM-диск).
Виртуальные устройства являются на самом деле просто оберткой, дополнительным слоем. В реальности драйверы логических устройств не работают с периферийными устройствами напрямую, они лишь переадресовывают запросы на драйверы других логических или физических устройств.
Драйверы физических устройств работают совместно с драйверами контроллеров, позволяя производить доступ к соответствующим устройствам на блочном уровне и предоставляя тем самым фактически прямой доступ к носителю – но, поскольку в большинстве случаев дисковые устройства имеют значительный объем, они часто делятся на разделы. Раздел является постоянным непрерывным фрагментом дискового пространства, местоположение которого на жестком диске записано в специальной области диска – таблице разделов.
Существует множество различных форматов разбиения диска на разделы – например, DOS partition table, BSD disklabels, UnixWare slices и многие другие. Как правило, во всех случаях соответствующая спецификация предусматривает возможность перечисления ограниченного количества разделов путем указания номеров первой и последней дорожек, занимаемых каждым из разделов. Каждый раздел видится как отдельное блочное устройство.
По традиции имена блочных устройств, соответствующих IDE-дискам и созданным на них разделам начинаются с hd и имеют вид /dev/hd<N>[<M>] где N – это буква, зависящая от контроллера и канала IDE, к которому подключено устройство, и режима устройства (master/slave). M – это некоторое число от 1 до 63 (фактически номер раздела на диске). Если число не указано, подразумевается весь диск. SCSI-дискам в /dev присваиваются имена sda, sdb, sdc и т.д. Ниже приводится небольшая таблица соответствия устройств и имен специальных файлов для IDE-дисков:
|
Контроллер |
Канал |
Режим |
|
Имя файла |
|---|---|---|---|---|
|
1 |
1 |
master |
primary master |
hda |
|
1 |
1 |
slave |
primary slave |
hdb |
|
1 |
2 |
master |
secondary master |
hdc |
|
1 |
2 |
slave |
secondary slave |
hdd |
|
2 |
1 |
master |
tertiary master |
hde |
|
2 |
1 |
slave |
tertiary slave |
hdf |
|
2 |
2 |
master |
quaternary master |
hdg |
|
2 |
2 |
slave |
quaternary slave |
hdh |
Когда драйвер блочного устройства, поддерживающего разбиение на разделы, в процессе загрузки или работы обнаруживает обслуживаемое им устройство, он считывает с него таблицу разделов, определяет ее разновидность и составляет таблицу разделов, запоминая начало и конец каждого из разделов. Впоследствии, если какая-либо программа производит обращение не непосредственно к физическому устройству, а к разделу на этом устройстве, драйвер с использованием построенной таблицы разделов определяет реальный адрес блока, над которым нужно произвести запрошенную операцию ввода/вывода.
Особой разновидностью раздела можно назвать расширенный (extended) раздел DOS. Расширенный разделы DOS может быть разбит на произвольное количество вложенных разделов, но в настоящий момент без использования LVM ядро Linux поддерживает до 63 разделов на IDE-диске и до 15 разделов на SCSI-диске. Такое ограничение связано с распределением мажоров и миноров блочных устройств.
Когда используется разбиение диска на разделы с использованием таблицы разделов DOS, следует помнить, что на жестком диске может быть не более 4 первичных разделов. Если администратору нужно, чтобы на жестком диске было более 4 разделов, необходимо объявить один из первичных разделов как расширенный раздел. Первичные разделы при использовании таблицы разделов DOS нумеруются от 1 до 4, логические разделы нумеруются начиная с 5, вне зависимости от количества первичных разделов. Только один из первичных разделов может быть объявлен расширенным.
Рассмотрим вывод команды fdisk, которая обычно используется в Linux для разбиения диска на разделы:
|
Как видно, на жестком диске IDE созданы 6 разделов, из них 4 первичных (разделы с номерами от 1 до 4) и два логических раздела с номерами 5 и 6, созданных внутри extended-раздела hda4.
Таблица разделов диска не может быть изменена в том случае, если хотя-бы один из разделов этого диска используется. В этом случае ядро продолжает использовать “старую” разметку (с которой оно работало до изменения), а изменения записываются на диск и вступают в силу после перезагрузки компьютера.
Если нет возможности запустить программу fdisk, то для получения данных о разметке блочных устройств на разделы и о состоянии блочных устройств, доступных в настоящий момент, можно использовать некоторые файлы из файловой системы /proc:
|
Например, эти данные могут быть использованы для восстановления таблицы разделов, если системный администратор по ошибке ее исправил.
Интересной особенностью таблицы разделов диска является то, что она не всегда изменяема. Это приводит к тому, что во многих случаях невозможно изменить размер какого-либо раздела или внести какие-либо другие изменения в таблицу разделов без перезагрузки – т.е. системный администратор может делать любые изменения, но они вступят в силу только после перезагрузки системы.
IDE-диски в настоящее время наиболее часто используются в офисных и домашних компьютерах, поэтому знать особенности распределения мажоров и миноров для этих типов устройств достаточно важно. IDE-устройства отличаются низкой ценой и неплохой скоростью передачи данных, но у этой шины есть архитектурные недостатки – например, все устройства работают со скоростью самого медленного из них, на один шлейф (на один канал) можно подключить только 2 устройства.
Всем устройствам, находящимся на одном канале IDE, присвоен один мажор. В настоящий момент ядро Linux выделяет для каждого устройства 64 минора, из которых первый минор зарезервирован для всего диска, и 63 минора остается для идентификации разделов. Таким образом, для IDE-дисков мажор идентифицирует канал, а по минору можно определить номер устройства на канале (режим master/slave) и номер раздела. Более детально это можно увидеть в следующей таблице:
|
Распределение номеров устройств для IDE-дисков |
|||||
|---|---|---|---|---|---|
|
Канал |
Устройство |
Раздел |
Major number |
Minor number |
Имя в /dev |
|
1 |
1 |
Весь диск |
3 |
0 |
/dev/hda |
|
Раздел 1 |
1 |
/dev/hda1 |
|||
|
Раздел 2 |
2 |
/dev/hda2 |
|||
|
Раздел 3 |
3 |
/dev/hda3 |
|||
|
Раздел 4 |
4 |
/dev/hda4 |
|||
|
... |
|
|
|||
|
Раздел 63 |
63 |
/dev/hda63 |
|||
|
2 |
Весь диск |
64 |
/dev/hdb |
||
|
Раздел 1 |
65 |
/dev/hdb1 |
|||
|
Раздел 2 |
66 |
/dev/hdb2 |
|||
|
Раздел 3 |
67 |
/dev/hdb3 |
|||
|
... |
|
|
|||
|
Раздел 63 |
127 |
/dev/hdb63 |
|||
|
2 |
1 |
Весь диск |
22 |
0 |
/dev/hdc |
|
Разделы |
1-63 |
/dev/hdc[1..63] |
|||
|
2 |
Весь диск |
64 |
/dev/hdd |
||
|
Разделы |
65-127 |
/dev/hdd[1..63] |
|||
По таблице становится видно, что на каждый 64-й минор происходит смена физического диска. Драйвер IDE в текущей версии ядра Linux поддерживает до четырех каналов IDE – т.е. до 8 устройств, по два устройства на канал..
Рекомендации, которую можно дать владельцам компьютеров с интерфейсом IDE: устройства по возможности рекомендуется держать на разных каналах. Если нет свободных каналов, то “быстрые” устройства лучше подключать на один канал, медленные – на другой.
Шина SCSI свободна от некоторых недостатков IDE, например количество устройств на одном канале может быть 15 (на самом деле 16, но одним устройством считается сам контроллер), все SCSI устройства работают на своей максимальной скорости, и ограничены только возможностями шины и контроллера – но SCSI-устройства и дороже, и поэтому шина SCSI используется в основном на серверах и рабочих станциях. Для SCSI-дисков ситуация немного меняется – мажоры не привязаны к контроллерам (т.е. один major number может использоваться дисками с разных хост-адаптеров). На каждом SCSI-диске система поддерживает до 16 разделов, а нумерация дисков производится в порядке их подключения по схеме, аналогичной IDE-дискам – но только переход на следующий диск происходит на каждом 16-м миноре (т.е. разделы на SCSI-дисках нумеруются от1 до 15). Увидеть это можно в следующей таблице и листинге /dev:
|
Распределение номеров устройств для SCSI-дисков |
||||
|---|---|---|---|---|
|
Номер диска в порядке подключения |
Major number |
Minor number |
Раздел |
Имя файла |
|
1 |
8 |
0 |
Весь диск |
sda |
|
1 |
Первый первичный |
sda1 |
||
|
2 |
Второй первичный |
sda2 |
||
|
3 |
Третий первичный |
sda3 |
||
|
4 |
Четвертый первичный |
sda4 |
||
|
5 |
Первый логический |
sda5 |
||
|
... |
|
|
||
|
15 |
Одиннадцатый логический |
sda15 |
||
|
2 |
8 |
16 |
Весь диск |
sdb |
|
17 |
Первый первичный |
sdb1 |
||
|
18 |
Второй первичный |
sdb2 |
||
|
19 |
Третий первичный |
sdb3 |
||
|
20 |
Четвертый первичный |
sdb4 |
||
|
21 |
Первый логический |
sdb5 |
||
|
... |
|
|
||
|
31 |
Одиннадцатый логический |
sdb15 |
||
В текущей версии ядро Linux поддерживает до 4096 SCSI-дисков – и для абсолютного большинства компьютеров этого должно быть достаточно. Очень важной особенностью SCSI-дисков является то, что мажор устройства, соответствующего физическому диску, не зависит от контроллера. В результате, если у вас есть 3 диска SCSI, то они всегда именуются sda, sdb и sdc, и если вы выключите компьютер и отключите первый диск, то после перезагрузки второй диск (который ранее назывался sdb) станет называться sda, а третий диск (который назывался sdc) станет называться sdb, поэтому при работе со SCSI-устройствами можно использовать devfs (которая позволяет адресовать диски через путь их подключения), либо использовать специализированные средства управления дисковым пространством, которые помечают носители и впоследствии правильно их идентифицируют даже после переименования устройств - например, средства md (software RAID) или LVM. Надо заметить, что в свете удаления devfs из основной ветви ядра, использование LVM стало фактически обязательным на серверах.
SATA, «осовремененная» версия интерфейса IDE, по своей структуре приблизилась к подсистеме SCSI. Поэтому в целях унификации подсистемы ввода-вывода в ядре Linux поддержка SATA была реализована через интерфейс SCSI., соответственно SATA-диски и контроллеры видятся ядром (и пользователем) как SCSI-устройства.
В новейших ядрах линейки 2.6 также появилась возможность работы с IDE-дисками через подсистему SCSI., и в новых дистрибутивах, таких как Fedora 7, даже обычные Parallel ATA (они же IDE) диски и контроллеры представляются как SCSI-устройства, что привело к унификации подсистемы дискового ввода-вывода, и теперь все диски и CD/DVD приводы для пользователя представляются как /dev/sdX или /dev/scdX. Драйверы для обычных контроллеров IDE, которые работают по новой схеме, начинаются с префикса pata, например: pata_via – это драйвер IDE-контроллеров с чипсетом VIA, а pata_piix - это дарйвера для IDE-контроллеров Intel, работающие через подсистему SCSI.
А говоря проще, это означает следующее – если у вас новый дистрибутив или имеются SATA-диски, вы можете смело работать со всеми дисками как со SCSI-устройствами.
Использование таблиц разделов для управления дисковым пространством – достаточно часто используемое решение. К сожалению, оно не свободно от определенных недостатков – например, нет возможности расширить раздел или уменьшить его размер, нет возможности создать один раздела на нескольких дисках и т.д. Решить эту задачу призван LVM (Logical Volume Manager).
LVM работает следующим образом: пользователь может пометить какие-либо блочные устройства как разделы, используемые LVM. Каждое из таких помеченых блочных устройств (их называют физическими томам,и или physical volumes) может быть присоединено к какой либо группе логических томов (logical volume groups). Внутри групп логических томов могут создаваться уже собственно логические тома (logical volumes). Дисковое пространство любого физического тома из некоторой группы может быть выделено любому логическому тому из этой группы. Реализовано это через так называемые “экстенты” (extents) дискового пространства. Физические тома LVM разбиваются на экстенты, после чего из экстентов и составляются логические тома. Именно за счет этого можно динамически менять конфигурацию дискового пространства – экстент может быть удален из одного тома, и добавлен к другому. Каждый объект LVM – будь то логический том, физический том или группа томов, имеет свой уникальный идентификатор.
Осуществляется это комплексно драйвером device mapper и специализированными программами из пакета lvm2. Эти программы читают файлы конфигурации и служебную информацию из заголовков физических томов, и на основании этой информации сообщают драйверу инструкции о том, из каких фрагментов каких блочных устройств каким именно образом должны быть скомбинированы логические тома, после чего драйвер для каждого логического тома создает отдельное блочное устройство. При обращении к такому блочному устройству device mapper определяет, на основании ранее переданных параметров к какому блоку какого блочного устройства на самом деле должен быть переадресован запрос, и запрашивает соответствующее блочное устройство для окончательного выполнения операции, после чего возвращает результат выполнения операции (прочитанные данные, сообщение об ошибке, код завершения операции) обратившейся программе.
Использование LVM позволяет гибко управлять распределением дискового пространства и избежать ограничений, связанных с классическим распределением дискового пространства путем создания разделов на жестких дисках. Единственное правило, которое я бы советовал соблюдать при использовании LVM – не создавать корневой раздел системы на логическом томе LVM: инициализации тома LVM, на котором находится корневая файловая система, необходимо вмешательство некоторых утилит, которые находятся на еще не смонтированной корневой файловой системы. Это решаемая проблема, но она потребует некоторого опыта.
Ниже идет пример создания и инициализации физического тома, группы томов и примеры нескольких операций с логическими томами. На первом фрагменте протокола продемонстрирована инициализация таблицы разделов для использования LVM. Порядок действий для использования LVM в общем случае следующий: один или несколько разделов жесткого диска с помощью fdisk помечаются как разделы LVM. Затем эти разделы инициализируются и передаются в группы томов, после чего их дисковое пространство можно использовать для создания логических томов:
|
В приведенном выше выводе fdisk видно, что на IDE-диске primary slave создан один раздел типа LVM (код типа раздела 0x8E). В следующем листинге показан процесс инициализации физического тома и создания группы томов aurora, в которую включается инициализированный командой pvcreate физический том /dev/hdb1:
|
Третий фрагмент демонстрирует создание нескольких томов и изменение размеров томов, проделанное с помощью LVM. В этом примере создается логический том размеров в 20GB, затем размер этого тома увеличивается до 30GB, создается еще один логический том, и после этого оба созданных логических тома удаляются.
|
Еще один фрагмент демонстрирует удаление группы томов и очистку физического тома:
|
Каждый логический том LVM имеет свой собственный minor number, а major number для всех томов LVM равен 253. Для доступа к томам LVM можно создавать блочные устройства с помощью команды mknod, а можно воспользоваться возможностями, предоставляемыми утилитой devlabel. Эта утилита создает символьные ссылки и каталоги внутри подкаталога /dev, причем для каждой группы томов в /dev создается каталог с именем этой группы, а логические тома представляются символьными ссылками из этих каталогов на блочные устройства, обслуживаемые драйвером device mapper, и тогда любой том LVM можно адресовать следующим путем: /dev/<имя_группы>/<имя_тома>. На листинге ниже показан пример того, как можно распределить дисковое пространство с помощью LVM:
|
Таким образом, возможности LVM позволяют системному администратору максимально эффективно использовать дисковое пространство, оперативно реагируя на меняющиеся условия эксплуатации. Еще одной интересной возможностью LVM является так называемый multipath I/O. В случае активации соответствующей опции в ядре device mapper знает о том, что физический том с некоторым UUID может быть доступен через несколько контроллеров, и в случае отказа одного контроллера динамически происходит переключение ввода-вывода на другой. Опытные системные администраторы также оценят такую возможность, как создание снимка (snapshot) логического тома: при создании снимка создается моментальная копия логического тома, которая начинает «жить» независимо от того тома, на основе которого она была создана:
|
В приведенном примере системный администратор «замораживает» файловую систему XFS, при этом драйвер XFS сбрасывает все закэшированные операции на диск, и после этого блокирует все процессы, которые пытаются писать на «замороженную» файловую систему. Затем системный администратор создает снимок тома home из группы томов chimera, на котором «живет» файловая система /home, и этот снимок называет home_snapshot, при этом на удержание копии измененных данных выделяется 10 гигабайт дискового пространства. После создания снимка файловая система /home размораживается, но каждый раз, когда будет переписываться какой-либо блок логического тома home, первоначальная версия изменяемого блока будет копироваться в те 10GB дискового пространства, которые мы выделили под снимок тома, и мы можем считать содержимое тома home_snapshot неизменным, и скопировать его на ленту. В процессе чтения, если читаемый блок не изменялся с момента создания снимка, то он читается из исходного тома (home), если же блок менялся с момента создания снимка, то используется его копия, хранимая в зарезервированном при создании снимка пространстве. После окончания копирования мы удаляем снимок командой lvremove.
Ядро Linux содержит средства для организации software raid (программных RAID-устройств). Эта возможность поддерживается драйвером устройств md. В отличие от device mapper, драйвер md умеет работать в “самостоятельном” режиме, получая конфигурацию из параметров, которые пользователь указал ядру при загрузке системы, что позволяет организовывать загрузку системы с RAID-устройств. Все устройства md имеют мажор 254 и миноры от 0 и до 16383.
В отличие от LVM, основной задачей которого является динамическое распределение дискового пространства (деление разделов на фрагменты и построение из фрагментов новых блочных устройств), задачей подсистемы RAID является построение новых блочных устройств путем объединения существующих.
Каждое из устройств, входящих в создаваемый дисковый массив, может определенным образом помечаться. Впоследствии эти метки (их также называют array superblocks) используются для повторной сборки массива. В частности, например, суперблок массива содержит его уникальный идентификатор, который можно использовать при сборке ранее созданного массива после перезагрузки. Если программный RAID-массив был помечен в процессе создания (т.е. на нем был создан суперблок массива), это дает возможность автоматической сборки массива вне зависимости от того, поменялся или нет порядок следования устройств. Например, такая необходимость может возникнуть в ситуации, когда порядок нумерации блочных устройств изменился – например, один из SCSI-дисков, участвовавших в построении массива, был удален.
Естественно, суперблок не является обязательным – то есть можно создавать массивы без суперблока, но управления ими может быть затруднено вследствие необходимости «руками» контролировать корректность указания устройств при переконфигурации массива.
Из интересных особенностей драйвера md стоит отметить то, что он поддерживает разбиение md-устройств на разделы, при этом минорные номера присваиваются разделам аналогично тому, как они присваиваются разделам на дисках IDE, т.е на каждом RAID-устройстве можно создать до 63 разделов. Определить минор раздела, созданного на RAID-устройстве, можно с помощью вычисления значения следующего выражения: 64 * N + M, где N – это номер массива (номер RAID-устройства) из диапазона 0 ... 255, а M – это номер раздела из диапазона 1 ... 63.
Следует сказать, что по умолчанию в большинстве дистрибутивов специальные файлы для разделов на md-устройствах не создаются, и их необходимо создать вручную командой mknod. В настоящий момент оптимальным, наверное, следует считать комбинирование использования LVM и md, что позволяет достигнуть надежности за счет дублирования данных средствами md, и гибкости распределения дискового пространства за счет возможностей LVM.
Драйвер md хорошо подходит для создания RAID-устройств уровней 0, 1 или 0+1, но не будет являться оптимальным вариантом в случае использования, например RAID уровня 5 (чередование данных по устройствам с вычислением контрольной суммы и кодом исправления ошибок), поскольку это создаст значительную нагрузку на процессор при большом объеме передаваемых данных. Возможно, что в таких случаях стоит подумать о приобретении аппаратного контроллера RAID - например, HP NetRaid (сделан на основе AMI MegaRAID) или Compaq Smart Array (сейчас называется HP Smart Array).
На листинге демонстрируется пример создания, активизации и остановки программных RAID-устройств уровня 0 и уровня 1 средствами драйвера md и системной утилиты mdadm. Утилита mdadm имеет конфигурационный файл /etc/mdadm.conf, но для того, чтобы проделать некоторые тесты и демонстрационные примеры нет необходимости его изменять.
В первом примере будем считать, что на жестком диске hdb создано два раздела, с которыми мы и будем экспериментировать. Для начала необходимо произвести инициализацию md-устройства. Соответственно, для успешной необходимо указать тип RAID-массива, специальный файл md-устройства, которое мы хотим инициализировать, и список блочных устройств, на которых будет располагаться получившийся массив:
|
Последняя команда демонстрирует активизацию массива путем указания имени md-устройства и нескольких блочных устройств, на которых оно базируется. Все остальные параметры (размеры блоков, разновидность RAID и т.д.) утилита mdadm извлекла из суперблока массива. Как уже отмечалось, суперблок массива содержит еще и уникальный идентификатор массива, что дает возможность проидентифицировать каждое исходное блочное устройство на предмет его принадлежности к какому-либо массиву. Ниже приведен пример вывода утилиты mdadm, демонстрирующий как можно получить некоторые полезные данные о массиве, а строка, содержащая UID массива выделена жирным текстом:
|
Впоследствии этот идентификатор может быть использован в файле конфигурации для утилиты mdadm. В конфигурационном файле /etc/mdadm.conf можно указать список устройств и правила их построения, после чего описанные в нем md-устройства будут автоматически собираться и разбираться без указания списка исходных устройств:
|
В листинге видно, что устройство массив md0 имеет указанный идентификатор, а также указано, что для построения массивов могут быть использованы все раделы диска hdb. В этом примере если системный администратор напишет команду mdadm –assemble /dev/md0, то mdadm просканирует все файлы устройств с именами, совпадающими с шаблоном /dev/hdb* и подключит к массиву md0 те из них, на которых будет найдена суперблок массива с тем идентификатором, который указан в параметре ARRAY для устройства /dev/md0.
Системный администратор, который хочет расположить корневую файловую систему на md-устройстве, должен указать ядру при загрузке какие именно физические блочные устройства должны входить в md-устройство, на котором содержится корневая файловая система. Обычно это делается путем загрузки ядра командной строкой с опциями следующего вида:
|
Данный пример приведен скорее как иллюстративный, поскольку в зависимости от опций, использованных при создании RAID-устройства, на котором расположена корневая файловая система, командная строка ядра может меняться. В современных дистрибутивах при необходимости инициализации md-устройств для загрузки системы, как правило код и утилиты инициализации устройства помещаются в initrd.
Суперблок массива записывается не в начале блочного устройства, а ближе к его середине или концу. Сделано это было для того, чтобы можно было создать RAID-массив с boot-сектором, который сможет быть прочитан не только ядром Linux с драйвером md, но и базовым загрузчиком BIOS, вследствие чего можно объединить в RAID-массив не разделы жестких дисков, а непосредственно физические диски. Тогда загрузчик, установленный в начало RAID-устройства, окажется установленным в начало жесткого диска, после чего можно использовать при загрузке ядра следующую командную строку:
|
Драйвер md также поддерживает возможность задания hotswap-устройств для массивов, т.е. резервных устройств, которые могут быть активизированы в при сбое одного из основных устройств в массиве.
Поддержка устройств software RAID в Linux дает возможность создавать серверы с высокой отказоустойчивостью и быстродействием.
В ядрах линейки 2.6 появилась еще одна подсистема по некоторым функциям аналогичная подсистеме MD, и называемая device-mapper. Это модульная компонентная подсистема, позволяющая с помощью специальных команд создать одно блочное устройство из нескольких кусков других блочных устройств, а также определить правила, по которым производится запись на эти «нижележащие» блочные устройства.
LVM работает именно через подсистему device mapper, и на самом деле все утилиты LVM на самом деле просто передают инструкции о том из каких фрагментов каких блочных устройств состоит какой том LVM в драйвер device mapper, в каком порядке осуществляется запись и чтение данных, и впоследствии при записи на том LVM или чтении с него, работа на самом деле ведется с устройствами, обслуживаемыми драйвером device mapper, который и делает всю работу.
Данная многоуровневая архитектура позволяет значительно упростить и таким образом значительно повысить стабильность работы системы, поскольку реализация нескольких небольших узкофункциональных компонентов в общей сложности содержит меньше ошибок, чем реализация всех этих функций в одной подсистеме.
Сегодня даже для дешевых современных материнских плат фирмы-производители часто декларируют «аппаратную поддержку RAID» и у многих пользователей этот факт вызывает недоумение – как же так, мой Linux не умеет работать с RAID?! На самом деле все проще – задекларированная и разрекламированная поддержка RAID-массивов на материнских платах для офисных и домашних компьютеров – это миф.
Вся поддержка RAID в таких «контроллерах» на самом деле представляют собой просто небольшое расширение в BIOS и без специальных драйверов в 32/64-битных операционных системах не работают, а все функции RAID для них выполняются драйвером. Если в Windows для каждого из таких контроллеров фирма-производитель пишет драйвер, то в Linux ситуация немного иная.
Для реализации возможности работы с такими псевдо-RAID контроллерами (иногда называемыми fake-RAID) была разработана утилита dmraid. При запуске она сканирует жесткие диски в поисках специальных блоков (функционально аналогичных суперблокам уже знакомых нам md-устройств), записываемых такими fake-RAID контроллерами, и если ей удалось распознать формат этого специального блока, то dmraid инструктирует подсистему device-mapper о том, в каком порядке следует считывать блоки с жестких дисков.
После этого device-mapper создает блочное устройство, при записи или чтение данных с которого данные автоматически читаются и пишутся так, как сделал бы это драйвер от производителя материнской платы или контроллера.
Ключевым (с нашей точки зрения) объектом сетевой подсистемы Linux является интерфейс. Сетевой интерфейс в Linux – это абстрактный именованный объект, используемый для передачи данных через некоторую линию связи без привязки к ее (линии связи) реализации. Конечно, сказано мудрено – но попробуем объяснить «на пальцах».
Например, если в системе существует интерфейс eth0, то в большинстве случаев на современных компьютерах он сопоставлен Ethernet-адаптеру, встроенному в материнскую плату. Интерфейс с именем ppp0 отвечает за некоторое соединение «точка-точка» с другим компьютером. Интерфейс с именем lo является виртуальным и представляет как бы замкнутый сам на себя (вход непосредственно подключен к выходу) сетевой адаптер.
Основная задача интерфейса – абстрагироваться от физической составляющей канала. То есть программы и система будут использовать один и тот же метод «отправить пакет» для отправки данных через любой интерфейс – хоть lo, хоть ethX, хоть pppY, и точно так же использовать один и тот же метод «принять пакет» - то есть создается унифицированный API передачи данных, независимый от носителя.
Для того, чтобы ознакомиться с интерфейсами, можно воспользоваться командой ifconfig:
|
В данном случае мы видим в системе два активных интерфейса, eth0 и lo, а также некоторую информацию об их состоянии, настройках и параметрах и состоянии аппаратуры для интерфейса eth0. В частности, поле Link encap характеризует тип интерфейса, HWAddr – аппаратный адрес устройства (например, MAC-адрес для Ethernet), MTU – максимальный размер передаваемого пакета. Также могут представлять интерес поля статистики – они сообщают, какой объем данных был передан и получен через соответствующий интерфейс.
Наиболее часто встречающиеся типы интерфейсов:
eth (Ethernet) – обычно соответствует отдельному сетевому адаптеру
ppp (Point-To-Point) – соединение точка-точка, например при коммутируемом доступе, но очень часто используется и при организации VPN
slip (Serial Line IP) – соединение точка-точка, устаревший протокол
wl (Wireless) – беспроводной интерфейс, обычно сопоставлен соответствующему адаптеру
lo (Loopback) – интерфейс-«петля», то есть что послал, то и получил - используется для общения между сетевыми приложениями в рамках одного компьютера
Команда ifconfig может также использоваться для остановки или активации интерфейса, а также изменения его параметров, связанных с протоколом IP:
|
Для управления параметрами других протоколов используются другие команды – например, ipx_config для управления параметрами, связанными с протоколом IPX. Рассмотрим также картинку, на которой приведена приблизительная схема взаимодействия различных драйверов и сетевых подсистем ядра:
Предположим, что приложение пытается отправить пакет. Перед отправкой через системные вызовы группы socket (bind, connect и пр.) приложение настраивает специальный файловый дескриптор. После окончания настройки каждый записанный в этот дескриптор пакет должен быть отправлен по сети получателю. Как движется пакет в нашей системе? Прежде всего, пакет попадает в драйвер протокола. Этот драйвер определяет через какой интерфейс должна производиться отправка, дописывает к пакету необходимые заголовки и отдает пакет на обработку соответствующему интерфейсу (точнее, ставит пакет в очередь, связанную с этим интерфейсом).
Что драйвер сделает с пакетом, это уже его дело. Например, драйвер интерфейса loopback этот пакет вынет из очереди и сразу поставит в очередь «принятых», откуда его впоследствии заберет драйвер протокола (левая цепочка на схеме). Драйвер интерфейса eth0 допишет к пакету заголовки Ethernet и передаст пакет драйверу сетевого адаптера, и уже тот непосредственно проинструктирует сетевой адаптер, откуда взять и как отправить пакет (правая цепочка). В средней же цепочке мы видим схему работы PPP, когда пакет помещается в очередь интерфейса ppp0, откуда его заберет демон pppd. Демон допишет в пакет нужные заголовки, и через символьный специальный файл /dev/ttyS0 передаст пакет драйверу COM-порта, а тот непосредственно будет работать с аппаратурой. Соответственно, при приемке данных цепочки проходятся в обратном порядке.
Маршрутизация транзитных IP-пакетов (не предназначенных для этого компьютера), или IP-форвардинг, является опциональной возможностью IP-стека Linux. По умолчанию функция форвардинга не активируется, и система не пересылает транзитные пакеты через свои интерфейсы, а только обрабатывает адресованные ей пакеты. Включение форвардинга IP-пакетов производится через параметр net.ipv4.ip_forward интерфейса sysctl. Если значение этого параметра равно 0, то форвардинг отключен, если же значение параметра не равно 0, форвардинг включен:
|
Кроме того, возможно разрешать или запрещать участие в форвардинге для каждого интерфейса индивидуально:
|
По умолчанию форвардинг включается и выключается для всех интерфейсов одновременно, но для отдельных интерфейсов возможно сменить флаг участия в форвардинге. Изменять параметры форвардинга может только системный администратор или пользователь, который имеет право записи в необходимые файлы интерфейса sysctl. Следующий листинг демонстрирует включение форвардинга через все интерфейсы путем вызова программы sysctl:
|
В процессе маршрутизации для выбора интерфейса и следующего узла для доставки пакета (next hop) ядро использует таблицу маршрутизации. Эта таблица представляет список критериев, в соответствии с которыми выбирается следующий узел. В частности, в таблице маршрутизации фигурируют следующие условия: адрес сети получателя пакета, маска подсети получателя пакета, IP-адрес следующего узла, метрика маршрута и служебные поля (например, тип и возраст записи). Таблица маршрутизации используется не только в IP-форвардинге, но и даже при простой отсылке IP-пакета для выбора интерфейса, через который будет производиться отсылка пакета.
Запись о сети с адресом 0.0.0.0 и маской подсети 0.0.0.0 называют маршрутом по умолчанию, или default route. Узел, чей адрес указан в поле gateway для маршрута по умолчанию, называют маршрутизатором по умолчанию, или default gateway или default router. В системе может быть произвольное количество маршрутов по умолчанию, но они должны быть как минимум с разными метриками. Для просмотра таблицы маршрутизации можно воспользоваться командой route. Эта команда позволяет оперировать с таблицей маршрутов, добавляя и удаляя из нее записи.
|
В данном выводе таблица упорядочена по маске подсети, что соответствует порядку ее просмотра ядром. Столбцы Destination и Genmask содержат адрес и маску сети получателя пакета, столбец Metric фактически указывает приоритет маршрута (маршрут с меньшей метрикой более приоритетен), поле Gateway указывает IP-адрес следующего узла для передачи пакета. Некоторые типы интерфейсов (в частности, интерфейсы типа точка-точка, или point-to-point) подразумевают, что на принимающем конце линии связи всегда находится не более одного узла, и поэтому в этой ситуации IP-адрес следующего узла можно не указывать. В данном случае мы видим, что в приведенном примере некоторые узлы доступны через интерфейс ppp0 типа точка-точка. В частности, именно из-за этого свойства приведенная выше таблица оказывается эквивалентна следующей ниже. Жирным шрифтом помечена измененная строка, демонстрирующая “точечную” природу PPP-соединения:
|
Специфика использования протокола PPP (обычно используемого при модемых соединениях) такова, что любой PPP-интерфейс является интерфейсом типа точка-точка, более того – PPP и расшифровывается как Point-to-Point Protocol. Также интерфейсами точка-точка являются интерфейсы SLIP (Serial Line IP) и практически все разновидности туннельных интерфейсов.
При деактивизации интерфейса из таблицы маршрутизации автоматически исключаются все маршруты, для которых в поле Iface был указан отключившийся интерфейс. Для некоторых типов интерфейсов при активизации в таблице маршрутизации также создаются служебные записи о маршрутах, которые нельзя удалить.
В большинстве случаев таблица маршрутизации имеет не слишком большой размер, но в некоторых ситуациях (в частности, на шлюзовых машинах в больших сетях) таблица может иметь весьма значительный размер и изменяется не “вручную” с помощью команды route, а специальными программами – демонами поддержки протоколов динамической маршрутизации. С некоторыми упрощениями алгоритм работы этих демонов можно описать следующим образом: демон “слушает” приходящие пакеты для обслуживаемых протоколов динамической маршрутизации, и по получении (или неполучении) такого пакета отдает ядру команду на изменение таблицы маршрутизации.
Следует также заметить, что команда route в режиме вывода таблицы маршрутизации фактически просто фильтрует и форматирует данные, содержащиеся в специальном файле, называемом /proc/net/route, используемом для доступа к таблице маршрутизации, ведущейся ядром.
Возможность инсталляции фильтров пакетов является очень интересной возможностью, предоставляемой стеком TCP/IP ядра Linux. Не углубляясь в детали просто отметим, что IP-стек Linux позволяет различным модулям установить “ловушки” (hooks) для пакетов. При этом каждый пакет, попадающий в такую ловушку, передается для обработки драйверу, установившему эту ловушку. Драйвер, в свою очередь, может проанализировать пакет, проделать какие-либо действия с пакетом, после чего вернуть код обработки, инструктируя таким образом ядро о том, что следует делать с пакетом дальше – вернуть ли отправителю сообщение об ошибке, прервать ли обработку и уничтожить пакет, либо продолжать обработку пакета обычным образом.
В настоящее время для фильтрации пакетов наиболее часто используются средства iptables. iptables – это название утилиты, которая позволяет настроить множество драйверов сетевой подсистемы NETFILTER ядра Linux, позволяющих осуществить анализ, произвести преобразование, или изменить обработку IP-пакетов. Основным объектом в iptables является цепочка правил (chain). Каждое правило в цепочке содержит набор условий совпадения (condition matches) и действие (action). Цепочки сгруппированы в таблицы (tables).
Действий есть две разновидности – прерывающие обработку пакета в цепочке, например действия DROP или ACCEPT, и не прерывающие обработку пакета цепочкой – например, LOG или MARK.
Цепочки используются для проверки пакетов – то есть пакет поочередно последовательно сравнивается с каждым из правил цепочки, и если он удовлетворяет всем условиям в правиле, к пакету применяется действие, указанное в этом правиле. Если действие является прерывающем, то на этом обработка пакета этой цепочкой заканчивается, если действие не прерывающее, то пакет продолжает проверяться этой же цепочкой.
Стандартные цепочки также содержат специальное неявное действие по умолчанию, называемое политикой цепочки (chain policy). Действие, указанное как политика цепочки, применяется ко всем пакетам, которые не попали ни под одно правило с “прерывающим” действием.
Подсистема пакетного фильтра содержит три таблицы, в каждой из которых содержатся несколько цепочек (наборов правил). Кроме того, администратор может создавать собственные цепочки правил. Ниже перечисляются стандартные таблицы и цепочки:
|
Таблица |
Назначение |
Цепочки |
Назначение |
|
mangle |
Модификация пакетов |
PREROUTING |
Модификация всех пришедших пакетов |
|
INPUT |
Модификация пакетов, пришедших на адрес компьютера |
||
|
FORWARD |
Модификация пакетов, которые должны быть отмаршрутизированы (пересланы на другой хост) |
||
|
OUTPUT |
Модификация пакетов, сгенерированных процессами данного хоста |
||
|
POSTROUTING |
Модификация всех переданных пакетов |
||
|
filter |
Фильтрация пакетов – принятие решения об их дальнейшей обработке или отказе от обработки) |
INPUT |
Фильтрация адресованных этому компьютеру пакетов |
|
OUTPUT |
Фильтрация сгенерированных этим компьютером пакетов |
||
|
FORWARD |
Фильтрация маршрутизируемых (транзитных) пакетов |
||
|
nat |
Трансляция адресов |
PREROUTING |
Трансляция адресов всех принимаемых пакетов |
|
FORWARD |
Трансляция адресов транзитных пакетов |
||
|
POSTROUTING |
Трансляция адресов всех передаваемых пакетов |
Таблица nat обладает “двойственным” действием, т.е. если вы включите преобразование для входящих пакетов, исходящие пакеты также будут модифицироваться, и наоборот. Таблицы mangle и nat изменяют пакеты, но mangle не ведет список изменений, т.е. является “однонаправленной” таблицей.
Рассмотрим, какой путь проходит пакет в цепочках и таблицах iptables. Для входящих пакетов (адресованных компьютеру, на котором активизирована поддержка iptables) верна следующая последовательность применения цепочек:
|
Для пакетов, отправляемых с компьютера, реализуется следующая цепочка обработки:
|
Пакеты, являющиеся транзитными (маршрутизируемыми), т.е. не адресованные фильтрующему компьютеру и не сгенерированные фильтрующим компьютером, проходят по следующей последовательности цепочек и таблиц:
|
Каждое правило в любой цепочке может ссылаться на одно из стандартных или дополнительных действий, либо на какую-либо пользовательскую цепочку. Основное различие между стандартными и дополнительными действиями в том, что стандартные действия могут указываться в правилах любых цепочек любых таблиц, а дополнительные действия можно указывать только для некоторых цепочек некоторых таблиц. Перечислим стандартные действия:
|
ACCEPT |
Прервать проверку пакета цепочкой и перейти к следующей в порядке обработки пакета стандартной цепочке |
|
DROP |
Прервать обработку пакета, сам пакет удалить |
|
RETURN |
Прервать проверку пакета цепочкой и вернуться к проверке вышестоящей цепочкой, а если действие встретилось в одно из стандартных цепочек, поступить с пакетом так, как предписано в политике цепочки (chain policy) |
|
QUEUE |
Передать пакет некоторому процессу для дальнейшей обработки |
Интересной особенностью также является то, что существуют так называемые target extensions, которые реализованы как модули и также могут использоваться для указания проводимого над пакетом действия. В частности, к таким действиям, например, относятся действия LOG – запротоколировать факт получения пакета, MASQUERADE – подменить IP-адрес отправителя пакета, MARK – пометить пакет и многие другие. Некоторые действия могут встречаться не во всех цепочках, а только в некоторых цепочках некоторых таблиц.
Еще одним специфическим действием можно назвать переход к пользовательской цепочке. При этом, если пакет в процессе обработки попадает под действие правила, у которого в качестве действия указан переход к другой цепочке, то пакет начинает проверяться ее правилами. Это часто используется, чтобы сходным образом обрабатывать некоторые виды пакетов.
Условия отбора делятся на две группы – стандартные условия, которые применимы ко всем пакетам, и расширенные условия, называемые также match extensions. Расширенные условия могут применяться не для всех пакетов, а только для некоторых из них – например, дополнительные условия для протокола UDP включают в себя адреса портов отправителя и получателя, а для ICMP – тип и код ICMP-сообщения.
Попробуем рассмотреть несколько простых примеров, достаточно часто используемых в реальных конфигурациях. Стоит заметить, что самостоятельная конфигурация пакетного фильтра требует некоторых (точнее, достаточно значительных) знаний сетевых протоколов, поскольку в конфигурации необходимо задавать множество критериев, которые сильно зависят от ситуации и от используемых сервисов.
Пример 1: простейшая конфигурация iptables для домашнего компьютера, подключенного к Internet. В этой конфигурации мы запретим все входящие соединения, а также все исходящие пакеты UDP кроме тех, которые необходимы для нормальной работы в Internet с использованием PPP-соединения. В этой конфигурации мы разрешаем передачу всех пакетов в рамках локальной машины, разрешаем исходящие TCP-пакеты, разрешаем входящие пакеты TCP для уже установленных соединений, и разрешаем передачу и прием UDP-пакетов для службы DNS и пакетов автоматической конфигурации соединения PPP (пакетов DHCP). Кроме того, следует разрешить прием управляющих пакетов ICMP и отправку запросов и прием ответов PING:
|
# iptables -P INPUT DROP # iptables -A INPUT -j ACCEPT -i lo # iptables -A INPUT -j ACCEP -p tcp ! --syn # iptables -A INPUT -j ACCEPT -p udp --source-port 53 # iptables -A INPUT -j ACCEPT -p udp --source-port 67 --destination-port 68 # iptables -A INPUT -j ACCEPT -p icmp --icmp-type destination-unreachable # iptables -A INPUT -j ACCEPT -p icmp --icmp-type time-exceeded # iptables -A INPUT -j ACCEPT -p icmp --icmp-type parameter-problem # iptables -A INPUT -j ACCEPT -p icmp --icmp-type echo-reply # iptables -P OUTPUT DROP # iptables -A OUTPUT -j ACCEPT -p tcp # iptables -A OUTPUT -j ACCEPT -p udp --destination-port 53 # iptables -A OUTPUT -j ACCEPT -p udp --destination-port 67 --source-port 68 # iptables -A OUTPUT -j ACCEPT -p icmp --icmp-type echo-request |
Пример 2: то же самое, что в примере 1, но все “отбитые” пакеты протоколируются. Для того, чтобы добиться такого эффекта, нужно создать дополнительную цепочку, которая будет протоколировать и удалять пакеты. Эту цепочку мы назовем KILLER – вполне обоснованно, не так ли? Кроме того, мы исправим политики стандартных цепочек так, чтобы запрещенные пакеты не удалялись, а “забрасывались” в созданную нами цепочку KILLER, а нашей основной цели (сначала протоколировать, потом удалить пакет) можно добиться просто указав два действия – сначала LOG, затем DROP. Поскольку действие LOG не является прерывающим обработку, мы получим требуемый нам эффект:
|
# iptables -N KILLER # iptables -A KILLER -j LOG # iptables -A KILLER -j DROP # iptables -P INPUT KILLER # iptables -A INPUT -j ACCEPT -i lo # iptables -A INPUT -j ACCEP -p tcp ! --syn # iptables -A INPUT -j ACCEPT -p udp --source-port 53 # iptables -A INPUT -j ACCEPT -p udp --source-port 67 --destination-port 68 # iptables -A INPUT -j ACCEPT -p icmp --icmp-type destination-unreachable # iptables -A INPUT -j ACCEPT -p icmp --icmp-type time-exceeded # iptables -A INPUT -j ACCEPT -p icmp --icmp-type parameter-problem # iptables -A INPUT -j ACCEPT -p icmp --icmp-type echo-reply # iptables -P OUTPUT KILLER # iptables -A OUTPUT -j ACCEPT -p tcp # iptables -A OUTPUT -j ACCEPT -p udp --destination-port 53 # iptables -A OUTPUT -j ACCEPT -p udp --destination-port 67 --source-port 68 # iptables -A OUTPUT -j ACCEPT -p icmp --icmp-type echo-request |
Пример 3: маскарад пакетов. Маскарадом называют преобразование IP-адресов проходящих пакетов так, чтобы они выглядели как отправленные с системы-маршрутизатора, а не с какого-либо узла “за” маршрутизатором. Достигается это путем изменения IP-адреса (и, возможно, номера порта) в “транзитных” пакетах. Собственно преобразование задается путем указания действий SNAT – замена адреса отправителя, DNAT – замена адреса получателя, или MASQUERADE – функционально аналогично SNAT, но без указания конкретного IP-адреса (IP-адресом для замены назначается IP-адрес интерфейса через который уходит пакет, со всеми отсюда вытекающими – например, если интерфейс меняет IP-адрес или просто деактивируется все «маскированные» через него соединения сбрасываются). Предположим, что наш “внешний” интерфейс имеет адрес 193.267.14.6, а внутренняя сеть имеет адрес 192.168.0.0/24. Тогда для того, чтобы дать всем компьютерам нашей сети доступ по протоколу TCP “наружу”, мы должны подать примерно следующую команду:
|
# iptables -A POSTROUTING -t nat -j SNAT -o ppp0 \ > --to-source 193.267.14.6 -p tcp \ > --source 192.168.0.0/24 \ > --destination ! 192.168.0.0/24 |
Если у нас внешний адрес динамический, а не статический (мы работаем по dialup – соединению), то мы можем использовать динамический маскарад без привязки к внешнему адресу – ну или с использованием динамической привязки, кому как больше нравится:
|
# iptables -A POSTROUTING -t nat -j MASQUERADE -o ppp0 \ > --source 192.168.0.0/24 \ > --destination ! 192.168.0.0/24 |
Действие SNAT более эффективно, MASQUERADE проще в использовании, но обладает рядом существенных недостатков (не вдаваясь в подробности, просто заметим, что на системе с несколькими интерфейсами и сложной таблицей маршрутизации проблемы почти наверняка будут). Особое внимание нужно обратить на указание -o ppp0, то есть действие применяется ТОЛЬКО для пакетов, отправляемых через интерфейс ppp0. Еще вы можете увидеть, что мы указываем это правило только один раз, и обратного к нему правила не строим - об этом позаботится функция connection tracking (отслеживание состояния соединений), и обратная замена адресов в отправляемых в ответ на наши запросы пакетах будет произведена системой автоматически.
Пример 4: “проброс” пакетов во внутреннюю сеть. Обычно это используется, если мы хотим перебросить пакеты, пришедшие на адрес маршрутизатора, на какую-либо из машин внутренней сети (например, так можно предоставить доступ ко внутреннему WWW-серверу). Достигается это использованием действия DNAT (destination NAT). В нашем случае мы перебрасываем все TCP-пакеты, пришедшие на интерфейс маршрутизатора ppp0 на порт 80, на порт 85 компьютера с адресом 192.168.0.6:
|
# iptables -A PREROUTING -t nat -j DNAT -i ppp0 \ > --to-destination 192.168.0.6:85 -p tcp --destination-ports 80 |
Конечно, приведенными примерами возможности iptables не исчерпываются, скорее даже наоборот – это лишь малая часть того, что умеет эта подсистема. Приведенные же примеры демонстрируют наиболее простые случаи, позволяющие составить некоторое представление об iptables и возможностях этой технологии.
В системах, основанных на RedHat Linux и его вариациях, есть специальный стартовый сценарий загрузки, также называемый iptables. Расположен он как правило в каталоге /etc/rc.d/init.d/. Этот сценарий при загрузке системы инсталлирует правила, созданные администратором, и его можно использовать для сохранения конфигурации iptables. В процессе конфигурации системный администратор задает конфигурацию подсистемы iptables, используя утилиту /sbin/iptables, а после окончания настройки дает команду /etc/rc.d/init.d/iptables save, после чего текущая конфигурация сохраняется в файл /etc/sysconfig/iptables. Существует также множество “фронтендов” для настройки iptables, которые могут использоваться начинающими пользователями и не слишком опытными администраторами, но “ручной” способ настройки все-таки предпочтительней, поскольку позволяет очень точно настроить подсистему iptables.
Linux – система многопользовательская. По умолчанию, большинство дистрибутивов используют «классический» набор файлов в которых хранится информация о пользователях и группах: /etc/passwd, /etc/group, /etc/shadow, /etc/gshadow. Во многих ситуациях этого вполне достаточно, но иногда возникает необходимость в интеграции Linux в более или менее чужеродное, либо просто распределенное окружение, и именно в этот момент к нам на помощь приходят такая интересная подсистема, как NSS – Name Service Switch. Основная задача NSS – создать модульное окружение для управления пользователями. Реализовано это посредством загружаемых библиотек. Основные вызовы NSS реализованы в библиотеке libc, а libc в свою очередь загружает и вызывает бакэнды
NSS:
При инициализации программы, так или иначе связанной с NSS, загружаются основная библиотека libc.so, которая считывает конфигурацию из файла /etc/nsswitch.conf, после чего также загружаются те библиотеки NSS, которые указаны в этом файле.
Впоследствии при работе программы, если программе требуется работать с именованными сущностями, соответствующие вызовы функций glibc будут обращаться к функциям NSS и использовать в те источники данных, которые указаны в nsswitch.conf.
В частности, через NSS можно разрешать (определять) имена и идентификаторы протоколов, номера портов служб (сервисов), имена и идентификаторы пользователей и групп, IP-адреса и имена компьютеров и некоторые другие данные.
Пример файла nsswitch.conf:
|
В данном примере указано, что для определения имен пользователей и групп используются сначала текстовые файлы и затем LDAP, для определения имен компьютеров и IP-адресов используются сначала текстовые файлы и затем DNS, для определения алиасов и настроек автоматического монтирования каталогов используются сначала текстовые файлы и затем служба NIS+.
Библиотеки бакэндов системы NSS хранятся в файлах libnss_XXX.so, где XXX – это имя бакэнда. Например libnss_files.so – это бакэнд NSS использующий в качестве источника данных текстовые файлы, libnss_db.so – бакэнд использующий файлы BerkleyDB, libnss_ldap.so – бакэнд позволяющий хранить данные в каталоге LDAP. Как правило, каждый бакэнд имеет свои дополнительные конфигурационные файлы.
Как следствие, если у вас возникла необходимость использовать вашу Linux-систему в сетевом или чужеродном окружении и обеспечить ее интеграцию с ним, вы можете воспользоваться NSS и получить доступ к информации через соответствующий бакэнд – например, для интеграции в среду Solaris, вы можете воспользоваться бакэндом NIS/NIS+, для интеграции в ActiveDirectory – бакэндом LDAP.
При этом модульность NSS позволяет вам объединять различные источники данных – например, использовать текстовые файлы и DNS для определения имен компьютеров, NIS для определения имен протоколов и сервисов, и текстовые файлы и LDAP для определения имен и идентификаторов пользователей и групп.
Подсистема PAM (Pluggable Authentification Modules) идейно очень схожа с NSS, но отличается от нее назначением. Основная задачам PAM – аутентификация пользователей (проверка паролей, прав доступ, ограничений и так далее). Как и NSS, PAM состоит из набора основных библиотек и бакэндов, причем необходимые бакэнды, порядок их вызова и некоторые опциональные параметры определяются в конфигурационных файлах PAM, обычно они расположены в каталоге /etc/pam.d. Главным отличием PAM от NSS (кроме естественно назначения) является то, что PAM является не составной и неотъемлемой частью libc, а отдельным множеством библиотек.
Основная часть стандартных утилит UNIX для управления пользователями и группами и получения информации о них, в большинстве дистрибутивов Linux общего назначения, адаптирована и собрана с поддержкой NSS и PAM. К таким утилитам относятся passwd, chsh, chfn, id, who и другие. NSS также используется даже такими утилитами как ls, find, ps – то есть всеми теми программами, которые отображают имя пользователя. Соответственно, если программа запрашивает у пользователя пароль – скорее всего она использует и NSS, и PAM (например XDM или GDM). Большинство программ в чьи функции входит обработка почты также используют NSS. Соответственно, можно уверенно говорить что подсистемы NSS и PAM и базовые знания об их предназначении на сегодняшний день являются необходимыми для администратора Linux-систем.
Большинство нынешних дистрибутивов по умолчанию устанавливают для пользователя графическую среду X11 (X11 Windows System), под управлением которой и выполняются все графические приложения. Как «внутри» устроена X11? Прежде всего, X11 – это распределенная модульная среда, состоящая из двух основных компонентов: X-сервера и X-клиента.
X-сервер – это программа, которая организует работу с устройствами ввода/вывода, производит отрисовку видимых элементов, запущена у пользователя и предоставляет свои ресурсы (те же самые устройства ввода-вывода) для X-клиентов. X-сервер загружает драйверы устройств (например видеокарты, мыши или клавиатуры), он же управляет переключением раскладок клавиатуры и т.п. Кроме того, X-сервер частично берет на себя функции работы со шрифтами. Задача использования аппаратного ускорения для отрисовки также является прерогативой X-сервера.
В современных дистрибутивах как правило используется открытый свободно распространяемый X-сервер называющийся Xorg. Его конфигурационный файл называется xorg.conf и расположен в каталоге /etc/X11. В конфигурационном файле описываются все устройства ввода, которые будет использовать X-сервер, настройки клавиатуры, драйвер видеокарты и многое другое. Более подробную информацию можно получить из справочного руководства [man Xorg, man xorg.conf].
X-клиент – это собственно пользовательская программа – браузер, почтовый клиент, видеоплеер, клиент мгновенных сообщений, игры, графические редакторы и просмотрщики и т.д.
Когда пользователь запускает графическое приложение, оно соединяется с X-сервером по стандартному протоколу X11, получает от X-сервера события о перемещении мыши, нажатиях кнопок клавиатуры и соответственно на них реагирует. Когда необходимо провести отрисовку, X-клиент отправляет соответствующие инструкции X-серверу, и уже X-сервер производит непосредственную отрисовку используя драйвер видеокарты. Команды протокола X11 могут передаваться как через разделяемую память или локальное соединение (если X-клиент и X-сервер запущены на одном компьютере), так и по сети – при этом X-клиент и X-сервер могут быть запущены на разных компьютерах.
X-сервер никаким образом не отвечает за внешний вид окна X-клиента – он отрисовывает все в точности так, как это указал клиент, более того – сам по себе X-сервер он не отрисовывает ни обрамлений окон, ни каких либо управляющих элементов, не обрабатывает никаких горячих клавиш – то есть он занимается только отрисовкой картинки присланной X-клиентом, а также чтением данных из устройств ввода и передачей соответствующих событий X-клиенту.
Обрамление окон, иконки рабочего стола, панели и кнопки – это все отрисовывается X-клиентами. Рассмотрим пример окна некоторого приложения (в нашем случае файлового менеджера Nautilus из состава среды GNOME):
На этой картинке на самом деле показан результат работы двух X-клиентов: собственно файлового менеджера nautilus (именно он управляет отрисовкой меню, строки статуса, панелей, иконок и так далее). Второй X-клиент – менеджер окон (window manager) под названием metacity нарисовал рамку окна и кнопки на этой рамке. При этом горячие клавиши для закрытия окна, сворачивания, перемещения и других операций с окном отрабатывает именно metacity, а горячие клавиши копирования файла, перехода по каталогам, навигации по меню, подсвечивание иконок и тому подобное отрабатывает уже сам nautilus.
Графической средой мы будем называть набор программ, для пользователя для выполнения им повседневных функций. Каждая из этих программ как правило является самостоятельным X-клиентом и может работать сама по себе, даже без своих «коллег по окружению», но будучи собранными вместе, они начинают предоставлять пользователю цельный и органичный интерфейс. Достигается это обычно следующим образом:
Все программы данного графического окружения используют одну и ту же библиотеку для отрисовки своих элементов управления
В графическое окружение включается какой-либо менеджер окон
Все программы для данного окружения разрабатываются с соблюдением определенных общих требований
В состав окружение включаются самостоятельные программы для выполнения базовых функций - текстовые и табличные процессоры, графический редактор, браузер, IM-клиент и другие
В состав окружения включаются служебные программы, предоставляющие пользователю возможность вызова других программ – например, приложение которое отрисовывает панель, на которой размещается кнопка для вызова меню со списком установленных программ и список окон
В состав окружения включают утилиты для настройки оборудования и дополнительных функций
В результате внешний вид окружения становится единообразным, а тот факт что оно состоит из множества небольших программ делает графическую среду гибкой в настройке и стабильной в работе. В то же время обширный набор программ для различных функций делает повзволяет графическому окружению удовлетворить большинство потребностей пользователя, а привычная вам картина GNOME или KDE, которую вы видите на экране в процессе работы, является результатом совместной работы множества X-клиентов соответствующего окружения... Или нескольких окружений одновременно.
Наиболее распространенные графические среды в Linux – это GNOME и KDE. И та и другая среда имеют свою библиотеку для отрисовки элементов управления внутри окна (для GNOME это GTK, для KDE это Qt), включают в свой состав почтовый клиент, браузер, мультимедиа-проигрыватель, клиент мгновенных сообщений и графический редактор, файловый менеджер (он же по совместительству отрисовывает иконки на рабочем стол и отвечает за фон рабочего стола), программу которая отрисовывает боковые панели и набор маленьких программ-апплетов, которые встраиваются при необходимости в панели, игры, программы управления для настройки окружения и менеджер окон.
Некоторые X-клиенты не входят в состав какого-либо окружения – например, браузеры Firefox и Opera, медиапроигрыватель Mplayer, офисный пакет OpenOffice.Org. Самое главное что следует запомнить – что графическое окружение, или графическая среда – это всего лишь набор программ, а не одна большая программа вида «все-в-одном», и вы можете, работая в основном в одном окружении, абсолютно спокойно использовать программы другого.
X11 – система многослойная, но внутренне логичная и понятная. Схематически ее можно изобразить следующим образом:

Когда приложение отрисовывает что-либо, оно обращается к своей базовой библиотеке, она в свою очередь переадресовывает вызов (или уже цепочку вызовов) в библиотеку libX11, которая использую X11 Core Protocol передает команды на X-сервер. X-сервер интерпретирует команды и передает их на отрисовку драйверам устройств вывода. Воздействие же пользователя на устройства ввода считываются X-сервером через драйвера устройств ввода, через X11 Core Protocol передаются X-клиенту, libX11 переводит команды протокола в события и передает события в тулкит, и уже тулкит передает события программе для того чтобы та на них отреагировала.
То как приложение выглядит – то есть внешний вид строк ввода, полос скроллинга, панелей и кнопок – за все это отвечает библиотека-тулкит. Два наиболее распространенных на сегодняшний день тулкита, Qt и GTK, примерно равны по возможностям – они обеспечивают переносимость приложений, поддержку «тем» внешнего вида, предоставляют программисту объектно-ориентированный интерфейс и некоторый набор служебных функций и возможностей.
Базовая библиотека X11 (libX11, или Xlib) позволяет программе абстрагироваться и не связываться с низкоуровневыми функциями протокола X11, и таким образом обеспечивает сетевую прозрачность X11, то есть позволяет программам работать как с локальным X-сервером, так и с находящимся на другом компьютере, причем делается это незаметно для программы.
С момента разработки в среде X11 отображение шрифтов управлял X-сервер. Приложение, когда ему необходимо вывести некоторый текст, просто инструктировало X-сервер «отобрази вот этот текст вот таким шрифтом в указанном месте». В ответ на это X-сервер выбирал из своей базы шрифтов наиболее подходящий, и использовал его для выполнения инструкций клиента, причем изначально эти шрифты были растровыми, то есть фактически содержали наборы заранее отрисованных глифов (символов).
Эта технология, называемая X Core Fonts, поддерживается в X11 и сейчас, поэтому в наборе пакетов любого дистрибутива всегда можно встретить наборы широко распространенных семейств растровых шрифтов – fixed, hevetica, times, courier. При этом каждый шрифт представляется множеством файлов, для различных сочетаний размера, ширины и начертания – например, если шрифт имеет десять вариантов размеров (от 8 до 18), две ширины (обычный и жирный) и два начертания (стандартное и курсив), то он будет представляться 40 файлами – по одному файлу для каждого из сочетаний размера, начертания и ширины.
Поскольку количество файлов получается очень большим, чтобы не устанавливать все эти шрифты на все компьютеры где запущены X-серверы, в систему X11 был введен такой объект как сервер шрифтов (font server). Системный администратор может настроить и запустить один сервер шрифтов для всей локальной сети, и указать X-серверу при запуске использовать шрифты с соответствующего сервера, что позволяет поддерживать на всех серверах один и тот же набор шрифтов с минимальными усилиями и избежать ситуации когда шрифт есть на одном компьютере, но его нет на другом.
В большинстве дистрибутивов Linux сервер шрифтов включен в поставку X11 по умолчанию, и называется xfs. Его конфигурационный файл как правило находится в каталоге /etc/X11/fs. В конфигурационном файле сервера шрифтов перечисляются каталоги с растровыми шрифтами, а в конфигурационном файле X-сервера указано, что основным источником шрифтов является сервер шрифтов,запущеный на этом же компьютере.
Такая методика позволяла добиться достаточно качественного отображения шрифта в большинстве случаев, но в то же время такие она имеет определенные недостатки – как известно, растровые шрифты очень плохо «вращаются» на угол не кратный 90 градусам, и плохо масштабируются, а с появлением устройств высокой четкости (LCD-мониторов) возникла необходимость еще и отрисовывать шрифты в «сглаженном» виде, с мягкими переходами цвета, чего растровые шрифты также предоставить не могли.
Наиболее распространенное приложение, использующее методику X Core Fonts – это графический эмулятор терминала xterm, который есть в составе всех дистрибутивов, или простейший менеджер графического входа в систему XDM.
Для устранения этого недостатка растровых шрифтов была разработана специальные библиотеки XFT и FreeType, которые обеспечивают отображение векторных шрифтов и реализацию таких возможностей как сглаживание шрифтов, их поворот на произвольный угол и хинтинг (подгонку символов шрифта друг к другу оптимальным для данного шрифта способом). Поскольку данная методика плохо согласовывалась с уже сложившейся шрифтовой архитектурой X11, отображение векторных шрифтов было возложено на X-клиента.
При этом схема отображения шрифта меняется: X-клиент не передает на X-сервер запрос на вывод текста указанным шрифтом, а самостоятельно отрисовывает необходимы глифы шрифта использую функции FreeType и XFT, и передает на X-сервер уже сформированную картинку, которую X-сервер и отображает. Вполне логично, что при использовании этой методики X-клиент должен иметь доступ к оригиналу векторного шрифта (обычно это файл) – поэтому современные дистрибутивы также содержат еще и наборы векторных шрифтов PostScript и TrueType.
Новые версии тулкитов GTK и QT используют именно эту методику, но поскольку существуют еще и устаревшие тулкиты, такие как Motif или Xview (OpenLook) и значительное количество приложений на них основанных, да и с точки зрения необходимой полосы пропускания сети технология поддержки растровых шрифтов имеет явное преимущество пред XFT и FreeType, поддержка технологии растровых шрифтов по-прежнему входит в X11 и будет оставаться в ней еще долго.
Протокол X11 не является замершим в своем развитии, но его развития ведется не путем изменения самого протокола, а путем внесения в протокол расширений – то есть дополнительных опциональных наборов команд и инструкций. Например, для поддержки непрямоугольных окон было введено расширение XShape, для поддержки проигрывания видеороликов введено расширение XVideo, для поддержки OpenGL было введено расширение GLX и так далее.
В штатную поставку X11 входит множество полезных программ, позволяющих получать служебную информацию об ваших настройках среды X11. Перечислим некоторые из них:
xterm – эмулятор терминала
xfontsel – интерактивный просмотр растровых шрифтов
xdpyinfo – вывод информации о ваших настройках среды X11 и задействованных расширениях
xwininfo – просмотр информации об указанном окне (положение, размер, класс окна и т.п.)
xwd – моментальный «снимок» окна
xwud – показ результатов работы xwd
xhost – управление контролем доступа X-клиентов к X-серверу
Существует особая разновидность X-клиентов, называемых менеджерами окон. Их основная функция – обеспечивать управление другими окнами – перемещением, изменением размеров, сворачиванием и разворачиванием окон, отрисовкой обрамлений окон, управление передачей фокуса от окна к окну а также управление Z-порядком размещения окон. Соответственно, в один момент времени для одного экрана может быть использован только один менеджер окон.
GNOME и KDE имеют свои собственные менеджеры окон – это metacity и kwin. Менеджеры окон являются взаимозаменяемыми – то есть вы можете выбрать и использовать тот из них, который вам больше нравится или кажется более удобным. Еще один распространенный (то есть наличествующий почти на всех UNIX-системах) менеджер окон – это twm. Крайне простой и примитивный, он тем не менее предоставляет пользователю базовые функции управления окнами и доступ к меню приложений.
Широкое распространение UNIX-систем привело к необходимости введения системы локализации – поддержки предпочитаемых пользователем стандартов на запись даты и времени, формата чисел, языка сообщения программ, обозначений национальной валюты и так далее.
В Linux стандартом на методику локализации является спецификация i18n. Не вдаваясь в подробности, мы попытаемся получить некоторое представление о том как это выглядит для пользователя.
Как конечные пользователи, мы можем ознакомиться с текущими настройками своей локали используя команду locale:
|
На самом деле, программа locale в корректно настроенной системе просто выведет вам значение соответствующих переменных окружения. Каждая из этих переменных отвечает за свой собственный аспект локализации, перечислим наиболее важные:
LANG – локаль по умолчанию, ее значение для различных аспектов может быть перекрыто путем установки отдельных переменных в нужное вам значение
LC_CTYPE – отвечает за классификацию символов и различия в их регистре
LC_NUMERIC – отвечает за представление и форматирование чисел
LC_TIME – отвечает за формат даты
LC_COLLATE – определяет настройки сравнения строк и символов, влияет на сортировку
LC_MONETARY – отвечает за представление национальной валюты
LC_MESSAGES – определяет язык сообщений и интерфейса
В примере мы видим что локалью по умолчанию через переменную LANG выбрана локаль ru_RU.UTF-8 (русский язык, соответствие российским стандартам, кодировка символов UTF-8), а в качестве языка интерфейса назначен английский язык в варианте используемом в США. Фактически это означает что все программы будут иметь английский интерфейс, но показывать дату, валюту, десятичную точку и сортировать строки они должны так как это принято в России.
В отличие от мира Windows, где язык сообщений программы как правило жестко забит в ресурсах, а ресурсы включены в исполняемый файл, в UNIX и Linux сообщения как правило содержатся в отдельных файлах и программа загружает текстовые строки для сообщений интерфейса основываясь на значениях переменных LANG и LC_MESSAGES. Это дает возможность обеспечить работу пользователей из разных стран на привычных им языках, не прибегая к установке нескольких копий операционной системы или нескольких экземпляров программы, каждый для своего языка.
Системному администратору Linux достаточно обеспечить наличие файлов сообщений нужной локали для используемых пользователем программ, и правильно установить переменные окружения, после чего пользователь оказывается в привычной для него языковой обстановке и работать с привычными форматами даты, валюты, в привычных единицах измерения и т.д.
Более того – можно установить значение некоторых переменных окружения в нужные значения непосредственно перед запуском программы – и тогда эта программа примет будет использовать указанные настройки локали только для этого запуска, например:
|
Таким образом, в Linux-системе возможно обеспечить одновременную работу пользователей в разных языковых окружениях, изменяя только изменение значений переменных окружения. В системах RedHat/Fedora общесистемные настройки локали хранятся в файле /etc/sysconfig/i18n, а пользователь может самостоятельно перекрыть их путем записи соответствующих значений в файле ~/.i18n:
|
В данном примере системная локаль ru_RU.UTF-8, но пользователь viking предпочитает работать в англоязычном интерфейсе, что и записал в своем персональном файле настроек локали.